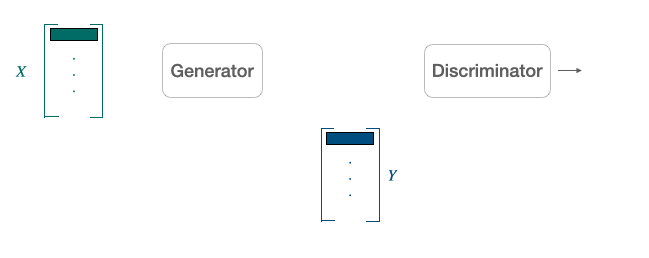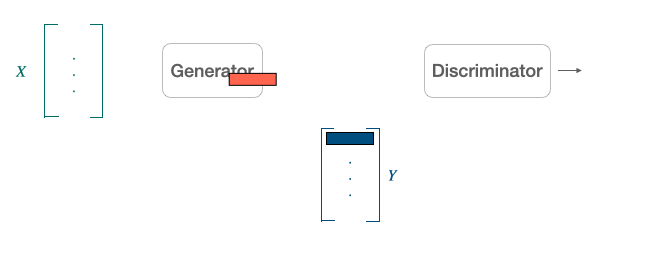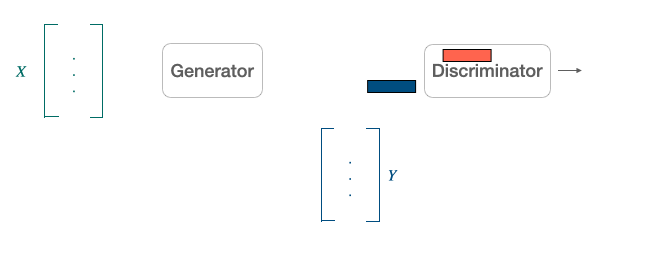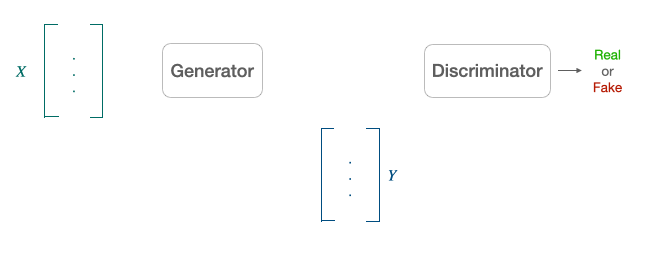
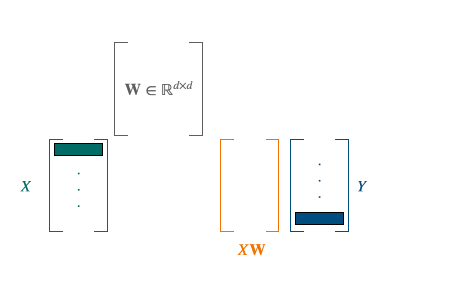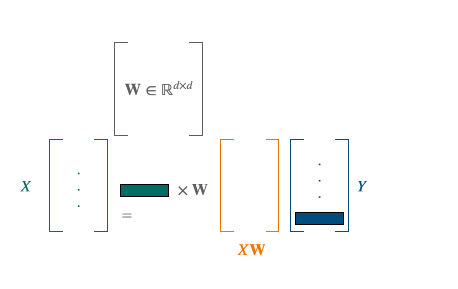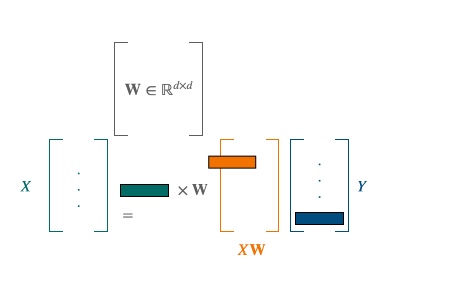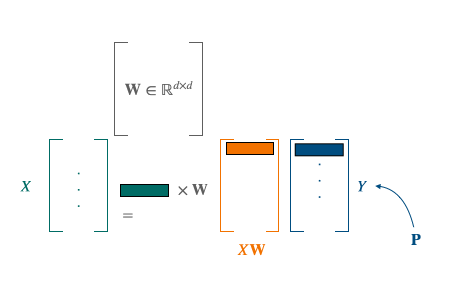At Flaneer, we are working on a new kind of workplace: a digital and remote one. Thanks to Flaneer, everyone can now turn its workstation (be it a laptop, a tablet or even a phone) into a powerful cloud-computer (or DaaS).
If you’d rather work with teammates, you can join their session and collaborate seamlessly. Talk with each other, annotate each other’s work live, send snapshots… Flaneer is much more than a simple VDI/virtualization service.
To make our platform as fast and scalable as possible, we built most of it on top of the Serverless Framework, with the help of AWS Lambda. You can find the code related to this article in the following Github repository.
AWS Lambda lets you run code in response to events and automatically manages the underlying compute resources for you. You can use it to create and deploy application back-ends quickly and seamlessly integrate other AWS services. You won’t have to manage any servers, and can simply focus on the code.
If your lambda functions are written in Python, you may need to use public libraries or private custom package. The goal of this article is to focus on AWS Lambda Shared Layers, a common place where you can store common functions and libraries for all of your lambda functions. We provide an overview of how to build such layers in this article! Our shared layers will be based on both public libraries, and on custom internal code. Let’s start with the architecture of shared layers!
Serverless & Shared Layers Architecture
Our shared layer will follow the simple structure:
Installing the external libraries is pretty easy, you can use 2 methods. The first one is to directly install them in the right location with the following command:
#pip3 install PACKAGE -t ./python/lib/python3.8/site-packages
#For example with stripe:
pip3 install stripe -t ./python/lib/python3.8/site-packages
You will have to repeat this operation for each python version your lambda functions will have to use. You can also make this process quicker by building a requirements.txt file like the following one:
You can build internal library as you would build any usual python project: simply use the folder “internal_lib” as the root folder of your project. You will then be able to use it in your lambda functions without any troubles.
This is is something that is super useful when your project starts to get bigger and bigger. Most of your lambda functions will start to reuse the same objects or functions. It can also allow you to make custom class for other AWS services, such as DynamoDB or Cognito for example.
Publish your Shared Layer
You can read more about how to publish your shared layer in:
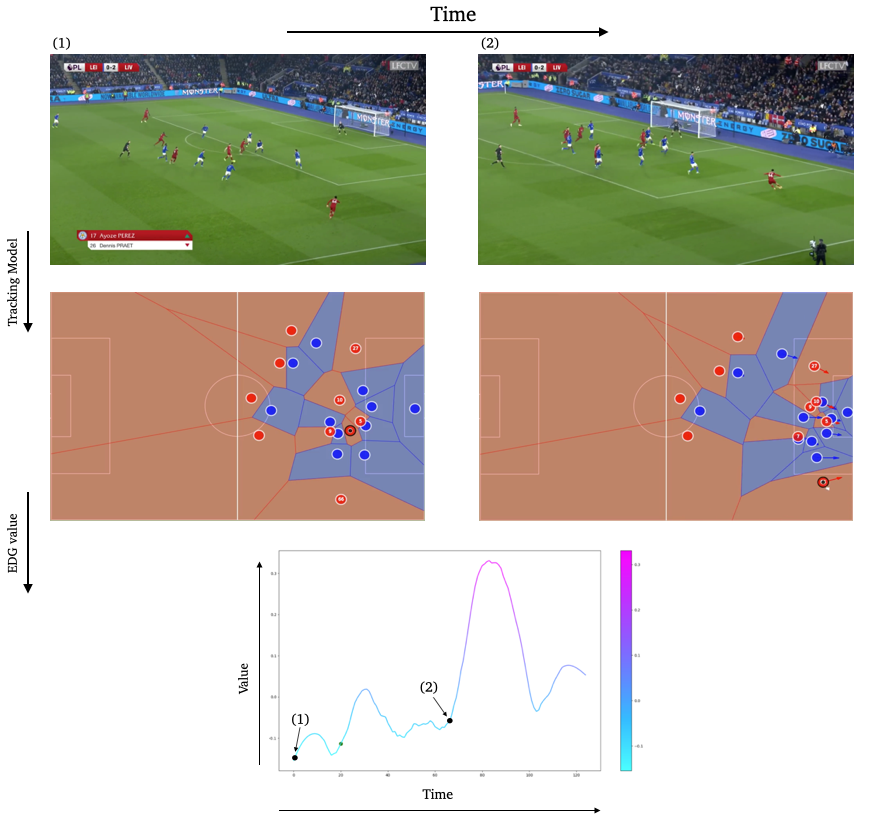
Evolution of our Tracking and EDG model over time. The EDG model learns to capture actions with potential in a very general manner, and compute such potential with the player coordinates our Tracking model gathers from the live Camera.
This blog post is the markdown version of a list of Jupyter Notebooks you can find inside Narya’s repository. This post allows to have each Notebook at the same place. It will probably be replaced by a Jupyter Book whenever I find the time and the solution to integrate them into this blog.
We tried to make everything easy to reuse, we hope anyone will be able to:
Use our datasets to train other models
Finetune some of our trained models
Use our trackers
Evaluate players with our EDG Agent
and much more
I now work at Flaneer, feel free to reach out if you are interested!
Narya
The Narya API allows you to track soccer player from camera inputs, and evaluate them with an Expected Discounted Goal (EDG) Agent. This repository contains the implementation of the following paper. We also make available all of our trained agents, and the datasets we used as well.
This Notebook’s goal is to allow anyone without any access to soccer data to produce its own and analyze them with powerful tools. We also hope that by releasing our training procedures and datasets, better models will emerge and make this tool better iteratively.
Framework
Our library is split in 2: one part is to track soccer players, another one is to process these trackings and evaluate them. Let’s start by focusing on how to track soccer players.
Installation
git clone && cd narya && pip3 install -r requirements.txt
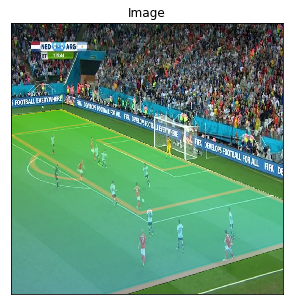
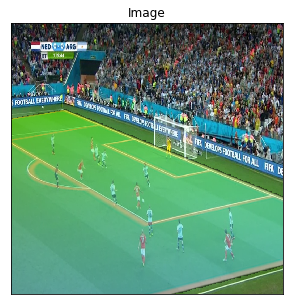
Let’s start by importing some libraries and an image we will use during this Notebook:
(a) The ET model computes the position of each entity. It then passes the coordinates to the online tracker to: (1): Compute the embedding of each player, (2): Warp each coordinate with the homography from HE.
(b) The HE starts by doing a direct estimation of the homography. Available keypoints are then predicted and used to compute another estimation of the homography. Both predictions are used to remove potential outliers.
(c) The REID model computes an embedding for each detected player. It also compares the IoU's of each pair of players and applies a Kalman Filter to each trajectory.
Players detections
The Player Detection model : $\mathbb{R} ^ {n \times n \times 3} \to \mathbb{R} ^ {m \times 4} \times \left[0,1\right] ^ {m} \times \left[0,1\right] ^ {m}$, takes an image as input, and predicts a list of bounding boxes associated with a class prediction (Player or Ball) and a confidence value. The model is based on a Single Shot MultiBox Detector (SSD), with an implementation from GluonCV.
You can easily:
Load the model
Load weights for this model
Call this model
We tried to keep a similar architecture for each model, even with a different framework.
For example, each model deals on itself with image preprocessing, reshaping, and so on: a simple __call__ is enough.
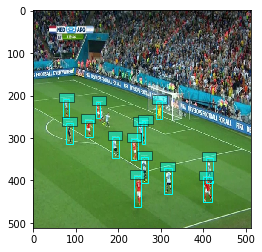
Now that we have players’ coordinates (and the ball position), we need to be able to transform them into 2D coordinates. This means finding the homography between our input image and a 2D representation of the field:
(left) Example of a planar surface (our soccer field) viewed by two camera positions: the 2D field camera and the Live camera. Finding the homography between them allows to produce 2D coordinates for each player.
(right) Example of points correspondences between the 2D Soccer Field Camera and the Live Camera.
Homography Estimations
We developed 2 methods to ensure more robust estimations of the current homography. The first one is a direct prediction, and the second one computes the homography from the detection of some particular keypoints. Let’s start with the direct prediction: $\mathbb{R} ^ {n \times n \times 3} \to \mathbb{R} ^ {3 \times 3}$.
The model is based on a Resnet-18 architecture and takes images of shape $(280,280)$. It was implemented with Keras. Let’s review its architecture, which is kept the same for each model, no matter its framework.
Each model is created with:
The shape of its input
If we want it pretrained or not
It then creates a model and a preprocessing function:
classDeepHomoModel:"""Class for Keras Models to predict the corners displacement from an image. These corners can then get used
to compute the homography.
Arguments:
pretrained: Boolean, if the model is loaded pretrained on ImageNet or not
input_shape: Tuple, shape of the model's input
Call arguments:
input_img: a np.array of shape input_shape
"""def__init__(self,pretrained=False,input_shape=(256,256)):self.input_shape=input_shapeself.pretrained=pretrainedself.resnet_18=_build_resnet18()inputs=tf.keras.layers.Input((self.input_shape[0],self.input_shape[1],3))x=self.resnet_18(inputs)outputs=pyramid_layer(x,2)self.model=tf.keras.models.Model(inputs=[inputs],outputs=outputs,name="DeepHomoPyramidalFull")self.preprocessing=_build_homo_preprocessing(input_shape)
Our second approach is based on keypoints detection: $\mathbb{R} ^ {n \times n \times 3} \to \mathbb{R} ^ {p \times n \times n}$ we predict $p$ masks, each mask representing a particular keypoint on the field. The homography is computed knowing the coordinates of available keypoints on the image, by mapping them to the keypoints coordinates of the 2-dimensional field. The model is based on an EfficientNetb-3 backbone on top of a Feature Pyramid Networks (FPN) architecture to predict each keypoint’s mask. We implemented our model using Segmentation Models.
Again, let’s start by quickly creating our model and making some predictions:
Here, we display a concatenation of each keypoints we predicted. Now, since we know the “true” coordinates of each of them, we can precisely compute the related homography parameters.
Notes: We explain here how the homography parameters are computed. This is a Supplementary Material from our paper and, therefore, can be skipped.
We assume 2 sets of points $(x_1,y_1)$ and $(x_2,y_2)$ both in $\mathbb{R}^2$, and define $\mathbf{X_i}$ as $[x_i,y_i,1]^{\top}$. We define the planar homography $\mathbf{H}$ that relates the transformation between the 2 planes generated by $\mathbf{X_1}$ and $\mathbf{X_2}$ as :
where we assume $h_{33} = 1$ to normalize $\mathbf{H}$ and since $\mathbf{H}$ only has $8$ degrees of freedom as it estimates only up to a scale factor. The equation above yields the following 2 equations:
where $\mathbf{h} = [h_{11},h_{12},h_{13},h_{21},h_{22},h_{23},h_{31},h_{32}]^{\top}$. We can stack such constraints for $n$ pair of points, leading to a system of equations of the form $\mathbf{A}\mathbf{h} = 0$ where $\mathbf{A}$ is a $2n \times 8$ matrix. Given the $8$ degrees of freedom and the system above, we need at least $8$ points (4 in each plan) to compute an estimation of our homography.
This is the method we use to compute the homography from the keypoints prediction.
Let’s do it and predict an homography from these keypoints:
In the next section, we will see how to use all of these models together to track players on a video.
Online Tracking
Given a list of images, we want to track players and the ball and gather their trajectories. Our model initializes several tracklets based on the detected boxes in the first image. In the following ones, the model links the boxes to the existing tracklets according to:
their distance measured by the embedding model,
their distance measured by boxes IoU’s
When the entire list of images is processed, we compute a homography for each image. We then apply each homography to the player’s coordinates.
"""
Images are ordered from 0 to 50:
"""imgs_ordered=[]foriinrange(0,51):path='test_img/img_fullLeicester 0 - [3] Liverpool.mp4_frame_full_'+str(i)+'.jpg'imgs_ordered.append(path)img_list=[]forpathinimgs_ordered:ifpath.endswith('.jpg'):image=cv2.imread(path)image=cv2.cvtColor(image,cv2.COLOR_BGR2RGB)img_list.append(image)
We first need to create our tracker. This object gathers every one of our models:
classFootballTracker:"""Class for the full Football Tracker. Given a list of images, it allows to track and id each player as well as the ball.
It also computes the homography at each given frame, and apply it to each player coordinates.
Arguments:
pretrained: Boolean, if the homography and tracking models should be pretrained with our weights or not.
weights_homo: Path to weight for the homography model
weights_keypoints: Path to weight for the keypoints model
shape_in: Shape of the input image
shape_out: Shape of the ouput image
conf_tresh: Confidence treshold to keep tracked bouding boxes
track_buffer: Number of frame to keep in memory for tracking reIdentification
K: Number of boxes to keep at each frames
frame_rate: -
Call arguments:
imgs: List of np.array (images) to track
split_size: if None, apply the tracking model to the full image. If its an int, the image shape must be divisible by this int.
We then split the image to create n smaller images of shape (split_size,split_size), and apply the model
to those.
We then reconstruct the full images and the full predictions.
results: list of previous results, to resume tracking
begin_frame: int, starting frame, if you want to resume tracking
verbose: Boolean, to display tracking at each frame or not
save_tracking_folder: Foler to save the tracking images
template: Football field, to warp it with the computed homographies on to the saved images
skip_homo: List of int. e.g.: [4,10] will not compute homography for frame 4 and 10, and reuse the computed homography
at frame 3 and 9.
"""def__init__(self,pretrained=True,weights_homo=None,weights_keypoints=None,shape_in=512.0,shape_out=320.0,conf_tresh=0.5,track_buffer=30,K=100,frame_rate=30,):self.player_ball_tracker=PlayerBallTracker(conf_tresh=conf_tresh,track_buffer=track_buffer,K=K,frame_rate=frame_rate)self.homo_estimator=HomographyEstimator(pretrained=pretrained,weights_homo=weights_homo,weights_keypoints=weights_keypoints,shape_in=shape_in,shape_out=shape_out,)
Creating model...
Succesfully loaded weights from /Users/paulgarnier/.keras/datasets/player_tracker.params
Succesfully loaded weights from /Users/paulgarnier/.keras/datasets/player_reid.pth
WARNING:tensorflow:No training configuration found in the save file, so the model was *not* compiled. Compile it manually.
Succesfully loaded weights from /Users/paulgarnier/.keras/datasets/deep_homo_model.h5
Succesfully loaded weights from /Users/paulgarnier/.keras/datasets/keypoint_detector.h5
We now only have to call it on our list of images. We manually remove some failed homography estimation, at frame $\in {25,…,30 }$ by adding skip_homo = [25,26,27,28,29,30] into our call.
100% (51 of 51) |########################| Elapsed Time: 0:00:00 Time: 0:00:00
Process trajectories
We now have raw trajectories that we need to process.
Fist, you can do several operations to ensure that the trajectories are functional:
Delete an id at a specific frame
Delete an id from every frame
Merge two ids
Add an id at a given frame
These operations are simple to do with some of our functions from narya.utils.tracker:
def_remove_coords(traj,ids,frame):"""Remove the x,y coordinates of an id at a given frame
Arguments:
traj: Dict mapping each id to a list of trajectory
ids: the id to target
frame: int, the frame we want to remove
Returns:
traj: Dict mapping each id to a list of trajectory
Raises:
"""def_remove_ids(traj,list_ids):"""Remove ids from a trajectory
Arguments:
traj: Dict mapping each id to a list of trajectory
list_ids: List of id
Returns:
traj: Dict mapping each id to a list of trajectory
Raises:
"""defadd_entity(traj,entity_id,entity_traj):"""Adds a new id with a trajectory
Arguments:
traj: Dict mapping each id to a list of trajectory
entity_id: the id to add
entity_traj: the trajectory linked to entity_id we want to add
Returns:
traj: Dict mapping each id to a list of trajectory
Raises:
"""defadd_entity_coords(traj,entity_id,entity_traj,max_frame):"""Add some coordinates to the trajectory of a given id
Arguments:
traj: Dict mapping each id to a list of trajectory
entity_id: the id to target
entity_traj: List of (x,y,frame) to add to the trajectory of entity_id
max_frame: int, the maximum number of frame in trajectories
Returns:
traj: Dict mapping each id to a list of trajectory
Raises:
"""defmerge_id(traj,list_ids_frame):"""Merge trajectories of different ids.
e.g.: (10,0,110),(12,110,300) will merge the trajectory of 10 between frame 0 and 110 to the
trajectory of 12 between frame 110 and 300.
Arguments:
traj: Dict mapping each id to a list of trajectory
list_ids_frame: List of (id,frame_start,frame_end)
Returns:
traj: Dict mapping each id to a list of trajectory
Raises:
"""defmerge_2_trajectories(traj1,traj2,id_mapper,max_frame_traj1):"""Merge 2 dict of trajectories, if you want to merge the results of 2 tracking
Arguments:
traj1: Dict mapping each id to a list of trajectory
traj2: Dict mapping each id to a list of trajectory
id_mapper: A dict mapping each id in traj1 to id in traj2
max_frame_traj1: Maximum number of frame in the first trajectory
Returns:
traj1: Dict mapping each id to a list of trajectory
Raises:
"""
Here, let’s assume we don’t have to perform any operations, and directly process our trajectories into a Pandas Dataframe.
We now have access to a dataframe with for each id, for each frame, the 2D coordinates of the entity.
df.head()
id
x
y
frame
1
1
78.251729
10.133520
2
1
78.262442
10.138342
3
1
78.308051
10.483425
4
1
78.356691
10.792084
5
1
78.379051
10.967897
Finally, this you can save this dataframe using df.to_csv('results_df.csv')
EDG
Now that we have some tracking data, it is time to evaluate them.
Theoretical framework
We assume $s_t \in \mathcal{S}$ is the state of the game at time $t$. It may be the positions of each player and the ball for example. Given an action $a \in \mathcal{A}$ (\eg a pass, a shot,etc), and a state $s’ \in \mathcal{S}$, we note $\mathbb{P} \colon \mathcal{S} \times \mathcal{A} \times \mathcal{S} \to [0,1]$ the probability $\mathbb{P} (s’ \vert s, a)$ of getting to state $s’$ from $s$ following action $a$.
%
Applying actions over $K$ time steps yields a trajectory of states and actions, $\tau ^{t_{0:K}} = \big(s_{t_0},a_{t_0}, … ,s_{t_K},a_{t_K} \big)$. We denote $r_t$ the reward given going from $s_t$ to $s_{t+1}$ (\eg $+1$ if the team scores a goal). More importantly, the cumulative discounted reward along $\tau ^{t_{0:K}}$ is defined as:
where $\gamma \in \left[0,1\right]$ is a discount factor, smoothing the impact of temporally distant rewards.
A policy, $\pi _{\theta}$, chooses the action at any given state, whose parameters, $\theta$, can be optimized for some training objectives (such as maximizing $R$). Here, a good policy would be a policy representing the team we want to analyze in the right manner. The \textit{Expected Discounted Goal} (EDG), or more generally, the state value function, is defined as:
\[V^\pi (s) = \underset{\tau \sim \pi}{\mathbb{E}} \big[ R(\tau) \vert s \big]\]
It represents the discounted expected number of goals the team will score (or concede) from a particular state. To build such a good policy, one can define an objective function based on the cumulative discounted reward:
To that end, we can compute the gradient of such cost function\footnote{Using a log probability trick, we can show that we have the following equality: $\nabla_\theta J(\theta) = \underset{\tau \sim \pi_\theta}{\mathbb{E}} \left[ \sum_{t=0}^T \nabla_\theta \log \left( \pi_\theta (a_t \vert s_t) \right) R(\tau) \right]$} $\nabla_\theta J(\theta)$ to update our parameters with $\theta \leftarrow \theta + \lambda \nabla_\theta J(\theta)$. In our case, the evaluation of $V^\pi$ and $\pi_\theta$ is done using Neural Networks, and $\theta$ represents the weights of such networks. At inference, our model will take the state of the game as input, and will output the estimation of the EDG.
Implementation
Our EDG agent was implemented using the Google Football library. We trained our agent against bots and against itself until it became strong enough. Such an agent can be seen on this youtube video.
Let’s start by importing some libraries:
Notes: Google Football is not compatible with Tensorflow 2 yet. We have to downgrade it to use our agent.
Homography Dataset: The homography dataset is made of pair of images,matrix in a .jpg,.npy format. The matrix is the homography associated with the image. They are normalized, meaning that homography[2,2] == 1.
Keypoints Dataset: We give here pair of images,xml file. The .xml files are made of the coordinates of each available keypoints on the image. We built utils function to read these files, and do so automaticaly in our Dataset class.
Tracking Dataset: Pair of images,xml files in a VOC format.
Training
Finally, we give here a quick tour of our training scripts.
# define optomizer
optim=keras.optimizers.Adam(opt.lr)# define loss function
dice_loss=sm.losses.DiceLoss()focal_loss=sm.losses.CategoricalFocalLoss()total_loss=dice_loss+(1*focal_loss)metrics=[sm.metrics.IOUScore(threshold=0.5),sm.metrics.FScore(threshold=0.5)]# compile keras model with defined optimozer, loss and metrics
model.compile(optim,total_loss,metrics)callbacks=[keras.callbacks.ModelCheckpoint(name_model,save_weights_only=True,save_best_only=True,mode="min"),keras.callbacks.ReduceLROnPlateau(patience=10,verbose=1,cooldown=10,min_lr=0.00000001),]model.summary()
We can easily build a Dataset and a Dataloader (handling batches):
This blog post contains an introduction to Unsupervised Bilingual Alignment and Multilingual Alignment. We also go through the theoretical framework behind Learning to Rank and discuss how it might help produce better alignments in a Semi-Supervised fashion.
This post was written with Gauthier Guinet and was initially supposed to explore the impact of learning to rank to Unsupervised Translation.
We both hope that this post will serve as a good introduction to anyone interested in this topic.
I now work at Flaneer, feel free to reach out if you are interested!
Introduction
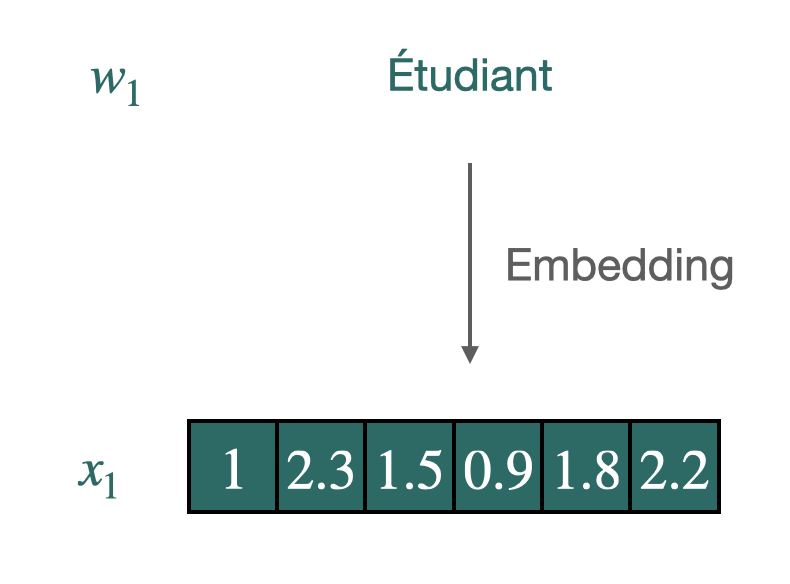
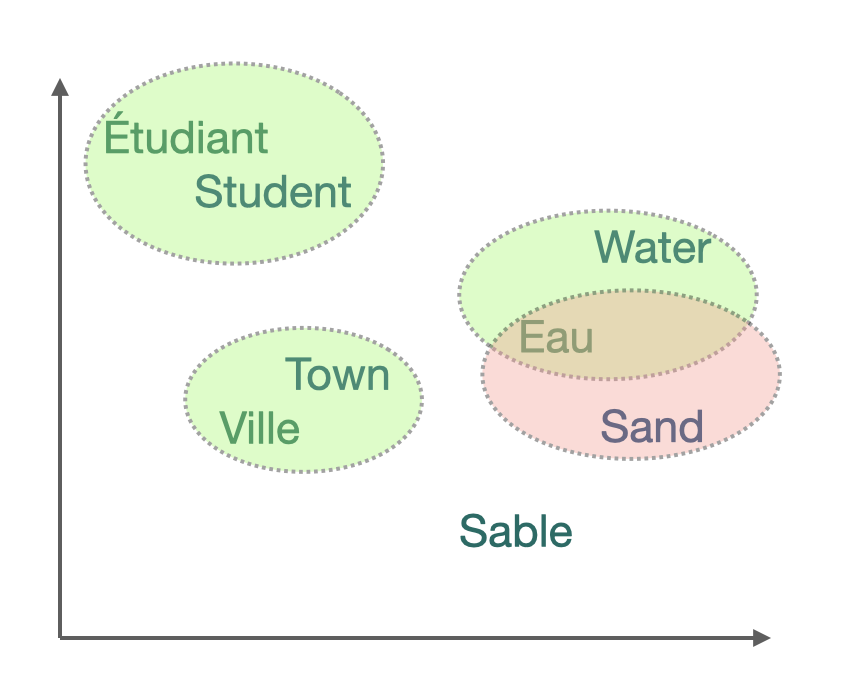
Example of the embedding of "Etudiant" in 6 dimensions.
Word vectors are conceived to synthesize and quantify semantic nuances, using a few hundred coordinates. These are generally used in downstream tasks to improve generalization when the amount of data is scarce. The widespread use and successes of these “word embeddings” in monolingual tasks have inspired further research on the induction of multilingual word embeddings for two or more languages in the same vector space.
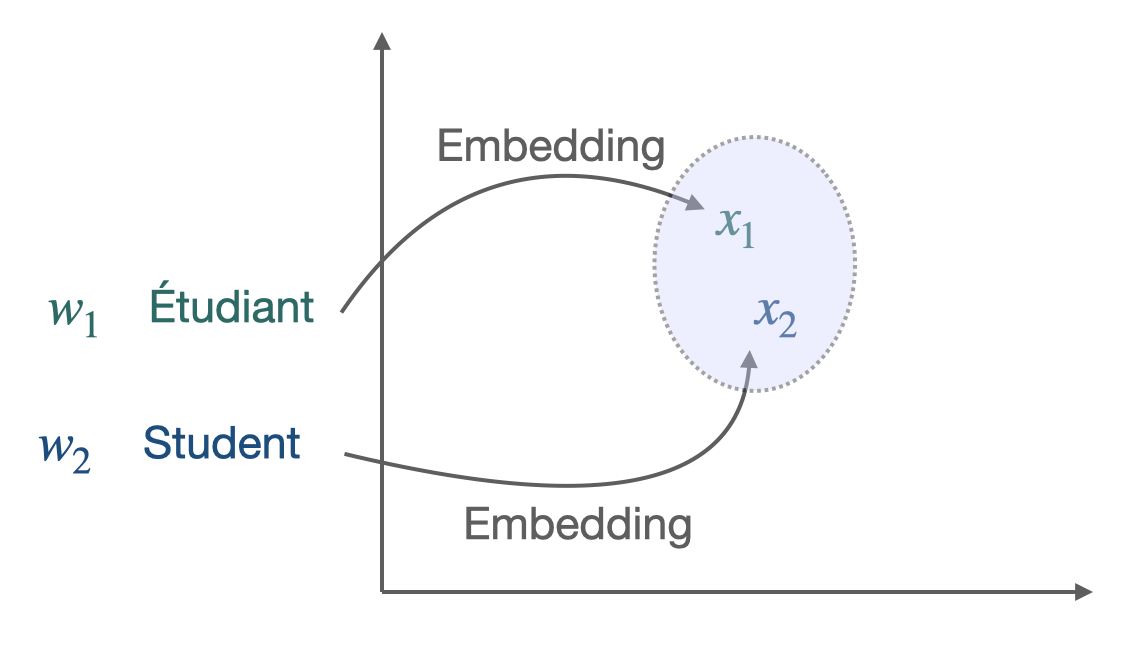
Words embeddings in 2 different languages but in the same vector space.
The starting point was the discovery [4] that word embedding spaces have similar structures across languages, even when considering distant language pairs like English and Vietnamese. More precisely, two sets of pre-trained vectors in different languages can be aligned to some extent: good word translations can be produced through a simple linear mapping between the two sets of embeddings. For example, learning a direct mapping between Italian and Portuguese leads to a word translation accuracy of 78.1% with a nearest neighbor (NN) criterion.
Example of a direct mapping and translation with a NN criterion for French and English.
Embeddings of translations and words with similar meaning are close (geometrically) in the shared cross-lingual vector space. This property makes them very effective for cross-lingual Natural Language Processing (NLP) tasks.
The simplest way to evaluate the result is the Bilingual Lexicon Induction (BLI) criterion, which designs the dictionary’s percentage that can be correctly induced.
Thus, BLI is often the first step towards several downstream tasks such as Part-Of-Speech (POS) tagging, parsing, document classification, language genealogy analysis, or (unsupervised) machine translation.
These common representations are frequently learned through a two-step process, whether in a bilingual or multilingual setting. First, monolingual word representations are learned over large portions of text; these pre-formed representations are actually available for several languages and are widely used, such as the Fasttext Wikipedia. Second, a correspondence between languages is learned in three ways: in a supervised manner, if parallel dictionaries or data are available to be used for supervisory purposes, with minimal supervision, for example, by using only identical strings, or in a completely unsupervised manner.
It is common practice in the literature on the subject to separate these two steps and not to address them simultaneously in a paper. Indeed, measuring the algorithm’s efficiency would lose its meaning if the corpus of vectors is not identical at the beginning.
Concerning the second point, although three different approaches exist, they are broadly based on the same ideas: the goal is to identify a subset of points that are then used as anchors points to achieve alignment. In the supervised approach, these are the words for which the translation is available. In the semi-supervised approach, we will gradually try to enrich the small initial corpus to have more and more anchor points. The non-supervised approach differs because there is no parallel corpus or dictionary between the two languages. The subtlety of the algorithms will be to release a potential dictionary and then to enrich it progressively.
We will focus on this third approach. Although it is a less frequent scenario, it is of great interest for several reasons. First of all, from a theoretical point of view, it provides a practical answer to a fascinating problem of information theory: given a set of texts in a totally unknown language, what information can we retrieve? The algorithms we chose to implement contrast neatly with the classical approach used until now. Finally, for very distinct languages or languages that are no longer used, the common corpus can indeed be very thin.
Many developments have therefore taken place in recent years in this field of unsupervised bilingual lexicon induction. One of the recent discoveries is the idea that using information from other languages during the training process helps improve translating language pairs.
This discovery led us to formulate the problem as follows: is it possible to gain experience in the progressive learning of several languages? In other words, how can we make fair use of the learning of several acquired languages to learn a new one? This new formulation can lead one to consider the lexicon induction as a ranking problem.
We will proceed as follows: First, we will outline state of the art and the different techniques used for unsupervised learning in this context. In particular, we will explain the Wasserstein Procrustes approach for bilingual and multi alignment. We then emphasize the lexicon induction given the alignment. We then present the Learning to Rank key concepts. We then discuss a method using learning to rank for lexicon induction, and then present some experimental results.
Unsupervised Bilingual Alignment
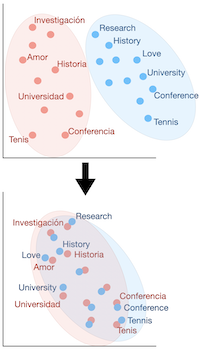
This section provides a brief overview of unsupervised bilingual alignment methods to learn a mapping between two sets of embeddings. The majority are divided into two stages: the actual alignment and lexicon induction, given the alignment. Even if the lexicon induction is often taken into account when aligning (directly or indirectly, through the loss function), this distinction is useful from a theoretical perspective.
Word embeddings alignment (in dimension 2).
Historically, the problem of word vector alignment has been formulated as as a quadratic problem.
This approach, resulting from the supervised literature, is then allowed to presume the absence of lexicon without modifying the framework. That is why we will deal with it first in what follows.
Orthogonal Procrustes Problem
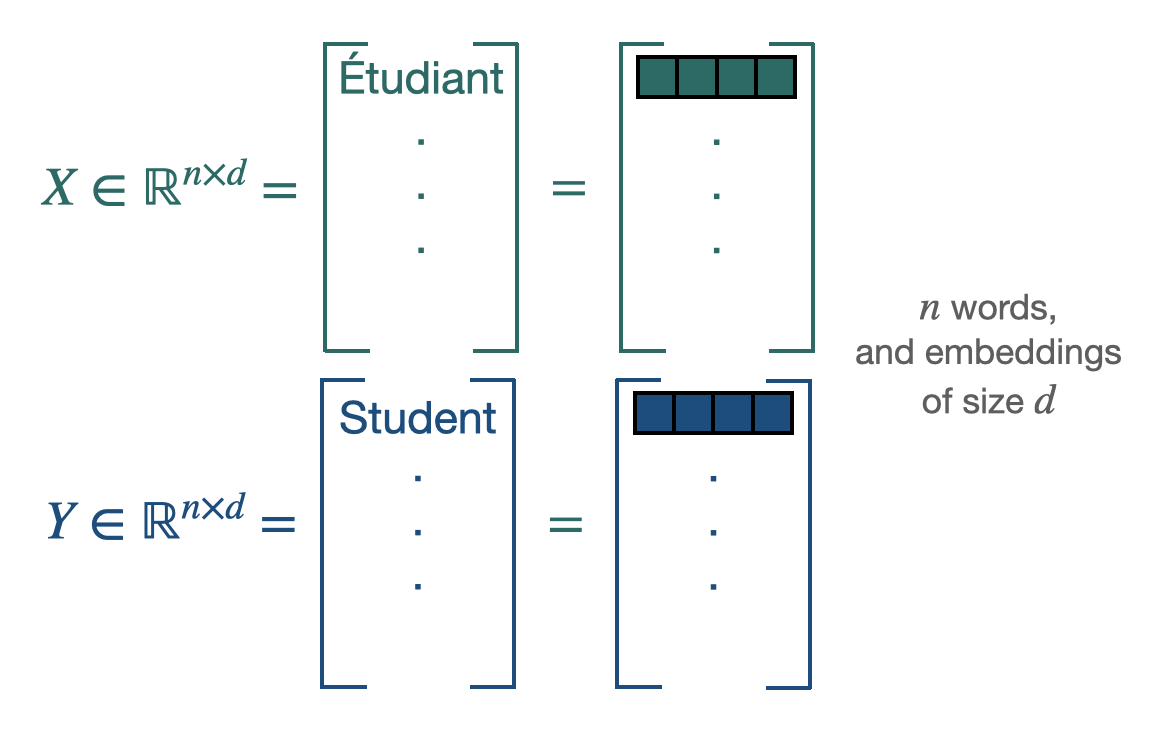
Set of n words (embeddings of dimensions d) for 2 languages.
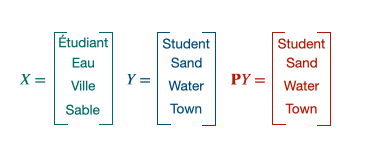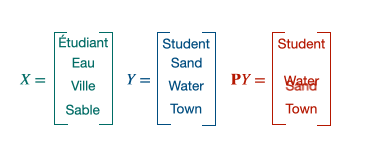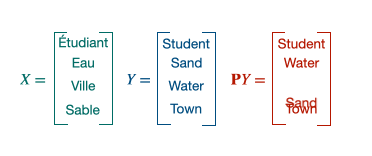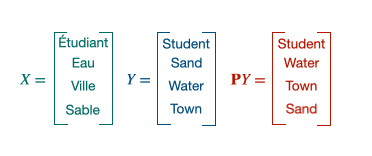
Procustes is a method that aligns points if given the correspondences between them (supervised scenario).
$\mathbf{X} \in \mathbb{R}^{n \times d}$ and $\mathbf{Y} \in \mathbb{R}^{n \times d}$ are the two sets of word embeddings or points and we suppose, as previously said, that we know which point X corresponds to which point Y. This leads us to solve the following least-square problem of optimization, looking for the W matrix performing the alignment [5]:
Operation applied for each word in the first language. The goal is to minimize the distance between the orange and the blue vectors.
We have access to a closed form solution with a cubic complexity.
Restraining W to the set of orthogonal matrices $\mathcal{O}_{d}$, improves the alignments for two reasons: it limits overfitting by reducing the size of the minimization space and allows to translate the idea of keeping distances and angles, resulting from the similarity in the space structure. The resulting problem is known as Orthogonal Procrustes. It also admits a closed-form solution through a singular value decomposition (cubic complexity).
Thus, if their correspondences are known, the translation matrix between two sets of points can be inferred without too many difficulties. The next step leading to unsupervised learning is to discover these point correspondences using Wasserstein distance.
Wasserstein Distance
In a similar fashion, finding the correct mapping between two sets of word can be done by solving the following minimization problem:
$\mathcal{P}_{n}$ containing all the permutation matrices, the solution of the minimization, $P_t$ will be an alignment matrix giving away the pair of words. This 1 to 1 mapping can be achieved thanks to the Hungarian algorithm.
It is equivalent to solve the following linear program:
The combination of the Procustes- Wasserstein minimization problem is the following:
To solve this problem, the approach of [5] was to use a stochastic optimization algorithm.
As solving separately those 2 problems led to bad local optima, their choice was to select a smaller batch of size b, and perform their minimization algorithm on these sub-samples. The batch is playing the role of anchors points. Combining this with a convex relaxation for an optimal initialization, it leads to the following algorithm:
Other unsupervised approaches
Other approaches exist, but they are currently less efficient than the one described above for various reasons: complexity, efficiency… We will briefly describe the two main ones below.
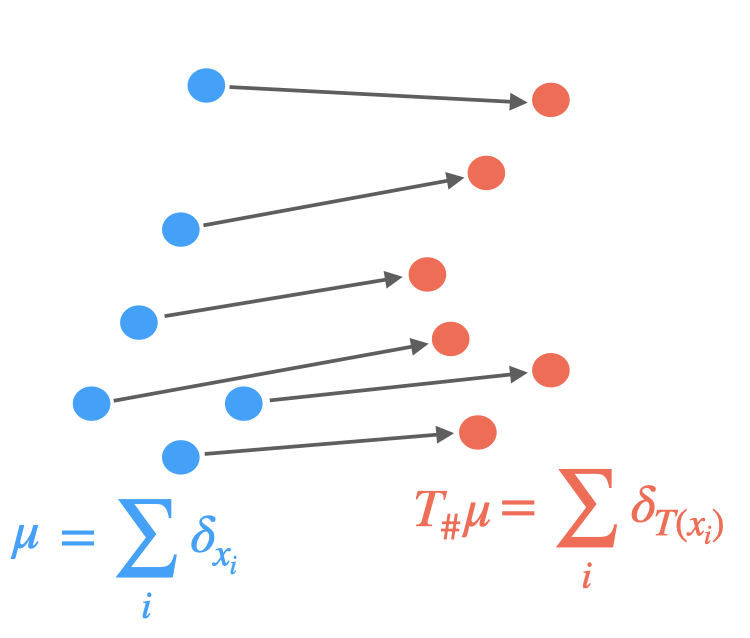
Optimal transport:
Optimal transport [6] formalizes the problem of finding a minimum cost mapping between two word embedding sets, viewed as discrete distributions. More precisely, they assume the following distributions:
and look for a transportation map realizing:
where the cost $c(\mathbf{x}, T(\mathbf{x}))$ is typically just $| T(\mathbf{x}) - \mathbf{x} |$ and $T_{\sharp}
\mu = \nu$ implies that the source points must exactly map to the targets.
Push forward operator
Yet, this transportation not always exist and a relaxation is used. Thus, the discrete optimal transport (DOT) problem consists of finding a plan $\Gamma$ that solves
where $\mathbf{C} \in \mathbb{R}^{n \times m}$, e.g., $C_{i j}=\left|\mathbf{x}^{(i)}-\mathbf{y}^{(j)}\right|$ is the cost matrix and the total cost induced by $\Gamma$ is:
where $\Gamma$ belongs to the polytope:
A regularization is usually added, mostly through the form of an entropy penalization:
Some works [7] are based on these observations and then propose algorithms, effective in our case, because they adapt to the particularities of word embeddings. However, we notice that even if the efficiency is higher, the complexity is redibitive and does not allow large vocabularies. Moreover, the research is more oriented towards improving the algorithm described above with optimal transport tools rather than towards a different path. This is why we will not focus in particular on this track. We should, however, note the use of Gromov-Wasserstein distance [8], which allows calculating the distance between languages innovatively, although they are in distinct spaces, enabling to compare the metric spaces directly instead of samples across the spaces.
Adversarial Training:
Another popular alternative approach derived from the literature on generative adversarial network [9] is to align point clouds without cross-lingual supervision by training a discriminator and a generator [10]. The discriminator aims at maximizing its ability to identify the origin of an embedding. The generator of W aims at preventing the discriminator from doing so by making WX and Y as similar as possible.
They note $\theta_{D}$ the discriminator parameters and consider the probability $P_{\theta_{D}}(\text { source }=1 | z)$ that a vector $z$ is the mapping of a source embedding (as opposed to a target embedding) according to the discriminator.
The discriminator loss can then be written as:
On the other hand, the loss of the generator is:
For every input sample, the discriminator and the mapping matrix $W$ are trained successively with stochastic gradient updates to minimize $\mathcal{L}_W$ and $\mathcal{L}_D$.
Yet, papers [10] on the subject show that, although innovative, this framework is more useful as a pre-training for the classical model than as a full-fledged algorithm.
Multilingual alignment
A natural way to improve the efficiency of these algorithms is to consider more than 2 languages.
Thus, when it comes to aligning multiple languages together, two principle approaches quickly come to mind and correspond to two optimization problems:
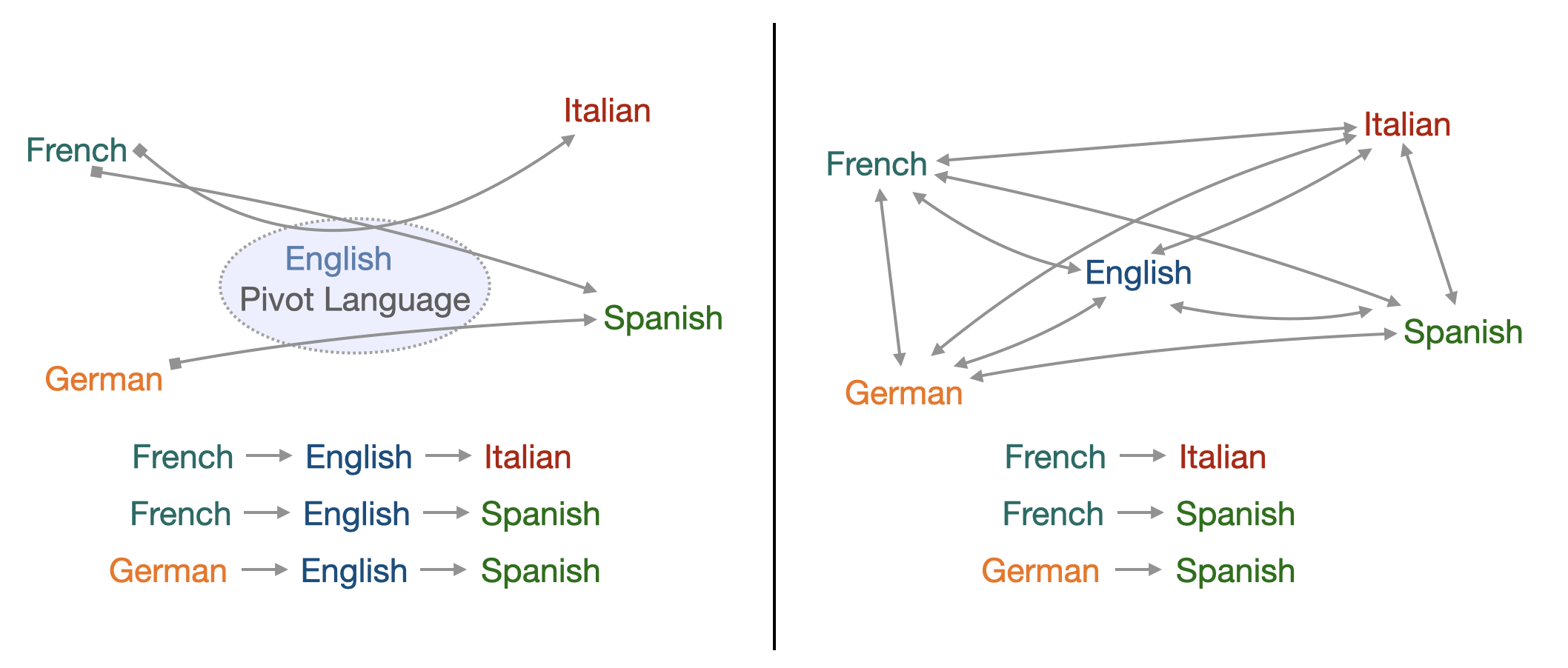
Align all languages to one pivot language, often English, without considering the loss function other alignments. This leads to low complexity but also to low efficiency between the very distinct language, forced to transit through English.
Align all language pairs by putting them all in the loss function, without giving importance to any one in particular. If this improves the efficiency of the algorithm, the counterpart is in the complexity, which is very important because it is quadratic in the number of languages.
Example of both approaches to align multiple languages.
A trade-off must therefore be found between these two approaches.
Let us consider $\mathbf{X}_i$ word embeddings for each language $i$, $i=0$ can be considered as the reference language, $\mathbf{W}_i$ is the mapping matrix we want to learn and $\mathbf{P}_i$ the permutation matrix. The alignment of multiple languages using a reference language as pivot can be resumed by the following problem:
As said above, although this method gives satisfying results concerning the translations towards the reference language, it provides poor alignment for the secondary languages between themselves.
Therefore an interesting way of jointly aligning multiple languages to a common space has been brought through by Alaux et al. [11].
The idea is to consider each interaction between two given languages, therefore the previous sum becomes a double sum with two indexes i and j. To prevent the complexity from being to high and to keep track and control over the different translations, each translation between two languages is given a weight $\alpha_{i j}$:
The choice of these weights depends on the importance we want to give to the translation from language i to language j.
The previous knowledge we have on the similarities between two languages can come at hand here, for they will have a direct influence on the choice of the weight. However, choosing the appropriate weights can be uneasy. For instance, giving a high weight to a pair of close languages can be unnecessary, and doing the same for two distant languages can be a waste of computation. To effectively reach this minimization, they use an algorithm very similar to the stochastic optimization algorithm described above.
At the beginning, we wanted to use this algorithm to incorporate exogenous knowledge about languages to propose constants $\alpha_{i j}$ more relevant and leading to greater efficiency. Different techniques could result in these parameters: from the mathematical literature such as the Gromov-Wasserstein distance evoked above or from the linguistic literature, using the etymological tree of languages to approximate their degree of proximity or even from both. In the article implementing this algorithm, it is specified that the final $\alpha_{i j}$ is actually very simple: N if we consider a link to the pivot or 1 otherwise. Practical simulations have also led us to doubt the efficiency of this idea. This is why we decided to focus on the idea below that seemed more promising rather than on multialignments.
Word translation as a retrieval task: Post-alignment Lexicon Induction
The core idea of the least-square problem of optimization in Wasserstein Procrustes is to minimize the distance between a word and its translation. Hence, given the alignment, the inference part first consisted of finding the nearest neighbors (NN). Yet, this criterion had a major issue:
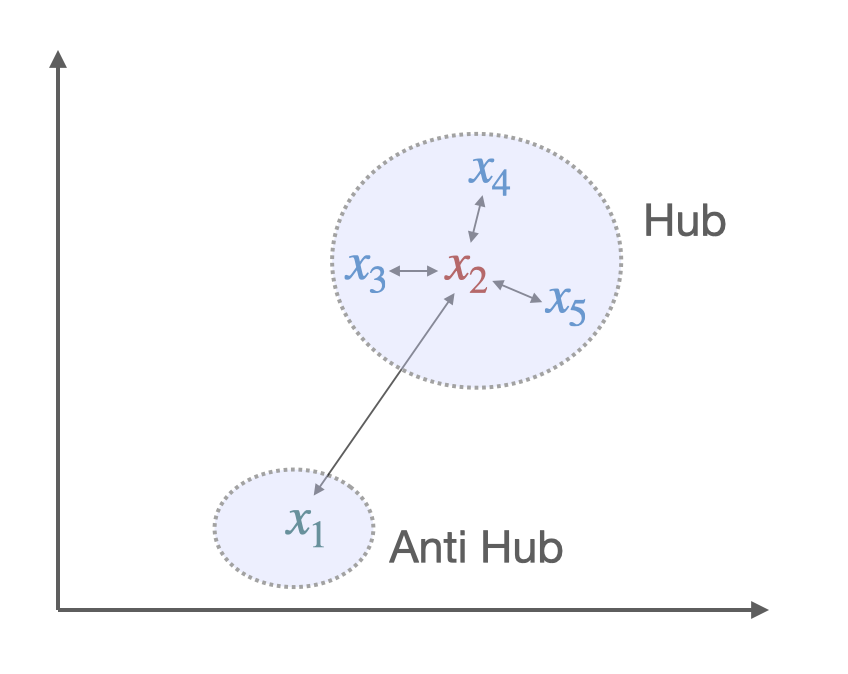
Nearest neighbors are by nature asymmetric: y being a K-NN of x does not imply that x is a K-NN of y. In high-dimensional spaces, this leads to a phenomenon that is detrimental to matching pairs based on a nearest neighbor rule: some vectors, called hubs, are with high probability nearest neighbors of many other points, while others (anti-hubs) are not nearest neighbors of any point. [12]
Two solutions to this problem have been brought through new criteria, aiming to give similarity measure between two embeddings, thus matching them appropriately. Among them, the most popular is Cross-Domain Similarity Local Scaling (CSLS) [10]. Others exist, such as Inverted Softmax (ISF)[13]. Yet, they usually require to estimate noisy parameter in an unsupervised setting where we do not have a direct cross-validation criterion.
The idea behind CSLS is quite simple: it is a matter of calculating a cosine similarity between the two vectors, subtracting a penalty if one or both of the vectors is also similar at many other points.
More formally, we denote by $\mathcal{N}_{\mathrm{T}} (\mathbf{W} x_s)$ the neighboors of $\boldsymbol{x}_S$ for the target language, after the alignment (hence the presence of $\mathbf{W}$).
Similarly we denote by $\mathcal{N}_{\mathrm{S}}(y_t)$ the neighborhood associated with a word $t$ of the target language. The penalty term we consider is the mean similarity of a source embedding $x_s$ to its target neighborhood:
where cos(…) is the cosine similarity.
Likewise we denote by $r_{\mathrm{S}}\left(y_{t}\right)$ the mean similarity of a target word $y_{t}$ to its neighborhood. Finally, the CSLS is defined as:
However, it may seem irrelevant to align the embedding words with the NN criterion metric and to use the CSLS criterion in the inference phase. Indeed, it creates a discrepancy between the learning of the translation model and the inference: the global minimum on the set of vectors of one does not necessarily correspond to one of the other. This naturally led to modify the least-square optimization problem to propose a loss function associated with CSLS.
By assuming that word vectors are $\ell_{2}-$ normalized, we have:
Similarly, we have:
Therefore, finding the $k$ nearest neighbors of $\mathbf{W} \mathbf{x}_i$ among the elements of $\mathbf{Y}$ is equivalent to finding the $k$ elements of $\mathbf{Y}$ which have the largest dot product with $\mathbf{W} \mathbf{x}_i$. This equivalent formulation is adopted because it leads to a convex formulation when relaxing the orthogonality constraint on $\mathbf{W}$. This optimization problem with the Relaxed CSLS loss (RCSLS) is written as:
A convex relaxation can then be computed by considering the convex hull of $\mathcal{O}_d$, i.e., the unit ball of the spectral norm. The results of the papers [10] point out that RCSLS outperforms state of the art by, on average, 3 to 4% in accuracy compared to benchmark. This shows the importance of using the same criterion during training and inference.
Such an improvement using a relatively simple deterministic function led us to wonder whether we could go even further in improving performance. More precisely, considering Word translation as a retrieval task, the framework implemented was that of a ranking problem. To find the right translation, it was essential to optimally rank potential candidates. This naturally led us to want to clearly define this ranking problem and use the state of the art research on raking to tackle it. In this framework, the use of simple deterministic criteria such as NN, CSLS, or ISF was a low-tech answer and left a large field of potential improvement to be explored.
However, we wanted to keep the unsupervised framework, hence the idea of training the learning to rank algorithms on the learning of the translation of a language pair, English-Spanish, for instance, assuming the existence of a dictionary. This would then allow us to apply the learning to rank algorithm for another language pair without a dictionary, English-Italian, for instance. Similarly to the case of CSLS, the criterion can be tested first at the end of the alignment carried out thanks to the Procrustes-Wasserstein method. Then, in a second step, it can be integrated directly through the loss function in the alignment step. The following will quickly present the learning to rank framework to understand our implementation in more detail.
Learning to Rank
A ranking problem is defined as the task of ordering a set of items to maximize the utility of the entire set. Such a question is widely studied in several domains, such as Information Retrieval or Natural Language Processing. For example, on any e-commerce website, when given a query “iPhone black case” and the list of available products, the return list should be ordered by the probability of getting purchased. One can start understanding why a ranking problem is different than a classification or a regression task. While their goal is to predict a class or a value, the ranking task needs to order an entire list, such that the higher you are, the more relevant you should be.
Theoretical framework
Let’s start by diving into the theoretical framework of Learning to Rank. Let $\psi := { (X,Y) \in \mathcal{X}^n \times \mathbb{R}^{n}_{+}}$ be a training set, where:
$X \in \mathcal{X}^n$ is a vector, also defined as $(x_1,…,x_n)$ where $x_i$ is an item.
$Y \in \mathbb{R}^{n}_{+}$ is a vector, also defined as $(y_1,…,y_n)$ where $y_i$ is a relevance labels.
$\mathcal{X}$ is the space of all items.
Furthermore, we define an item $x \in \mathcal{X}$ as a query-documents pair $(q,d)$.
The goal is to find a scoring function $f : \mathcal{X}^n \rightarrow \mathbb{R}^{n}_{+}$ that would minimizes the following loss :
where $l : (\mathbb{R}^{n}_{+})^2 \rightarrow \mathbb{R}$ is a local loss function.
One first et very important note is how $f$ is defined. This could be done in two ways:
We consider $f$ as a univariate scoring function, meaning that it can be decomposed into a per-item scoring function with $u : x \mapsto \mathbb{R}_+$. We will have $f(X) = [u(x_0), \cdots , u(x_n)]$.
We consider $f$ as a multivariate scoring function, meaning that each item is scored relatively to every other item in the set, with $f$ in $\mathbb{R}^{n}_{+}$. This means that changing one item could change the score of the rest of the set.
While the first option is simpler to implement, the second one is much closer to reality, as an item’s relevance often depends on the distribution its in. For example, an article’s relevance to an e-commerce query will always depend on what the website offers you next to it.
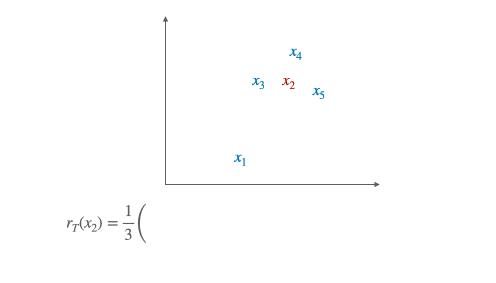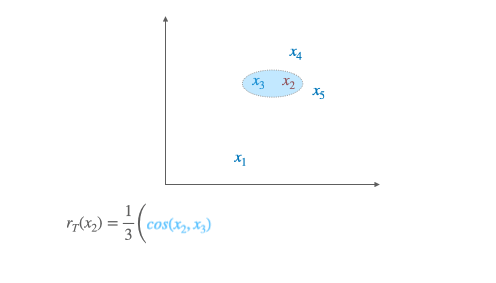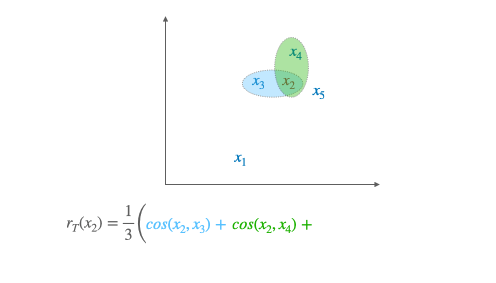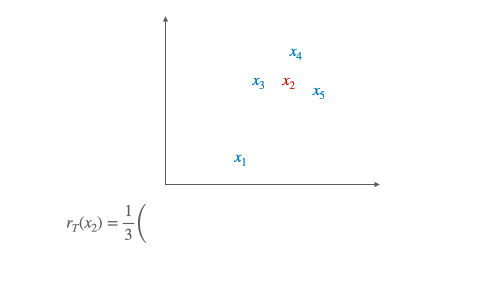
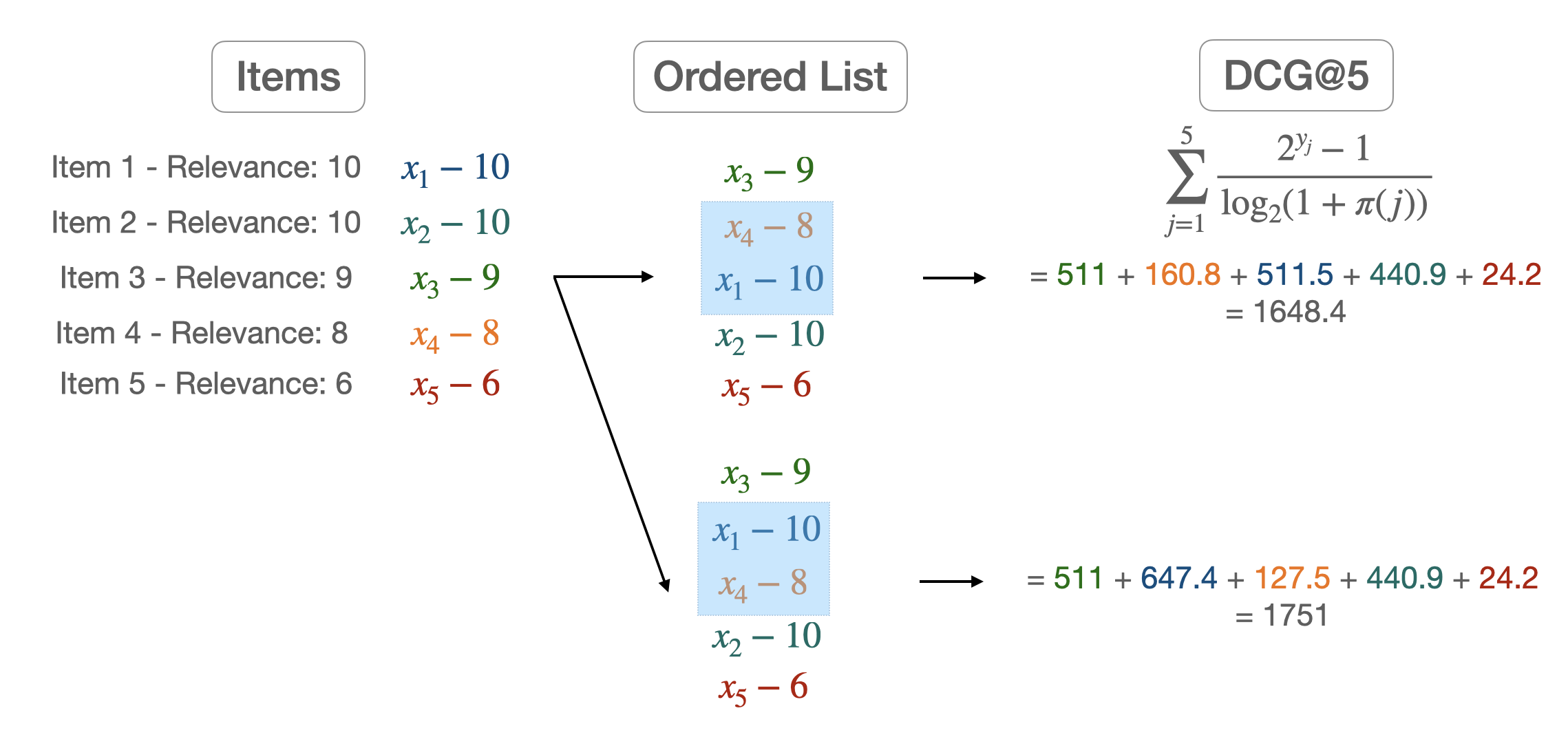
We now have to define some metrics in order to judge how good a ranking is. We start by defining the Discounted Cumulativ Gain (DCG) of a list:
where:
$Y = (y_1,…,y_n)$ are the ground truth labels
$\pi(j)$ is the rank of the j-th item in X
$\frac{1}{ln_{2}(1+\pi(j))}$ is the discount factor
$k$ is how much we want to go deep into the list. A low value of $k$ means that we want to focus on how well ranked the start of our list is.
Most of the time however we want to compare this metric to the DCG obtained from the ground truth labels. We then define:
where $\pi^*$ is the item permutations induced by Y.
Loss functions
In
we defined $l$ as a loss function between two ordered sets of items. One approach could be to use the metrics defined above, but as they are non-differentiable, this is not a feasible choice. Therefore, we have to develop some sort of surrogate loss function, differentiable, and with the same goal as our metric. Before diving into the possible approaches, one must define what pointwise, pairwise, and listwise loss functions are.
A pointwise loss will only compare one predicted label to the real one. Therefore, each item’s label is not compared to any other piece of information.
A pairwise loss will compare 2 scores from 2 items at the same time. With the pairwise loss, a model will minimize the number of pairs in the wrong order relative to the proper labels.
A listwise loss can capture differences in scores throughout the entire list of items. While this is a more complex approach, it allows us to compare each score against the others.
Let’s give an example for each sort of loss function, starting with a pointwise one. The sigmoid cross entropy for binary relevance labels can be defined as:
where $p_j = \frac{1}{1 + e^{-\hat y_j}}$ and $\hat Y$ is the predicted labels for each item from one model.
The pairwise logistic loss [1] is a pairwise loss function that compares if pair of items are ordered in the right order. We can define it as:
where $\mathbb{I}_{x}$ is the indicator function.
Finally, a listwise loss function like the Softmax cross-entropy [2] can be defined as:
All of these loss functions are surrogates that try to capture the goal of our metrics. Another approach would be to define a listwise loss function, as close as our metrics as possible. For example, one could try to build a differentiable version of the NDCG [3]
ApproxNDCG: a differentiable NDCG
Let’s take a query $q$, and define several useful functions:
the relevance of an item $x$ regarding of the fixed query $q$, and
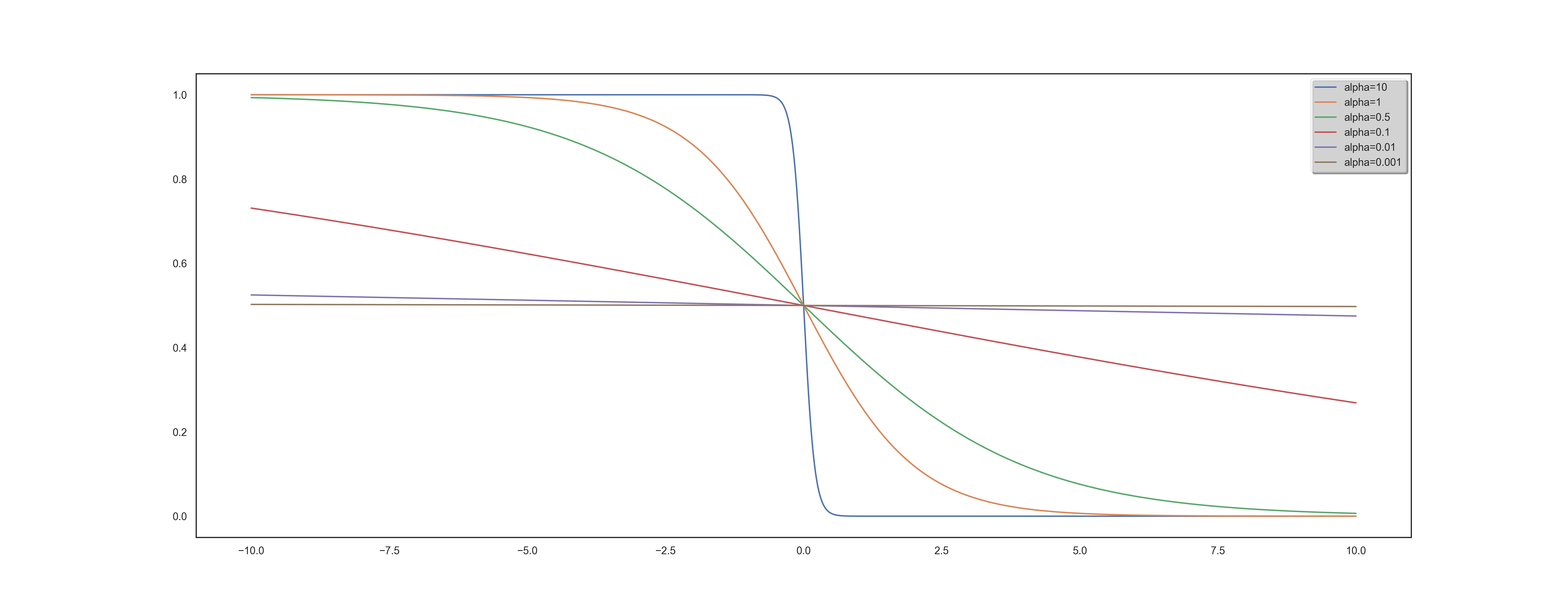
the position of $x$ in the ranked list $\pi$ and finally, $\mathbb{I}_{{\pi(x) \leq k}}$ still represents the indicator function of the set ${\pi(x) \leq k}$. The idea is to use an differentiable approximation of the indicator function. One can show that we have the following approximation:
where $\alpha$ is a hyperparameter.
Example of approximation of the Indicator function for various values of alpha.
For a fixed query, we can re-define the DCG metric with the following equality :
We now have to get an approximation of the $\pi$ function. The idea here is to get back to an indicator function since it is possible to compute them. We will be using the following equality :
where $s_x$ is defined as the score given to $x$ according to $f$, and define an approximation of $\pi$ with:
We can now define our differentiable version of the DCG metric by using these approximations.
RUBI: Ranked Unsupervised Bilingual Induction
Motivations: Let’s describe more precisely the functioning of our algorithm. Two points guided our approach:
From a linguistic point of view, there is obviously a learning to learn phenomenon for languages. We observe that by assimilating the structure of the new language, its grammar, and vocabulary to one of the already known languages, it is easier for us to create links that help learning.
It is the search for these links that motivate us. We are convinced that they can be useful when inferring vocabulary.
Improvement induced by using the CSLS criterion suggests that there are complex geometrical phenomena (going beyond the existence as mentioned above of hubs) within the representations of languages, both ante, and post-alignment. Understanding these phenomena can lead to significantly increased efficiency.
Framework: Our goal is the same as for unsupervised bilingual alignment: we have a source language A and a target language B with no parallel data between the two. We want to derive an A-B dictionary, a classic BLI task. Our study’s specificity is to assume that we also have a C language and an A-C dictionary at our disposal. To set up the learning to learn procedure, we proceed in 2 steps:
Learning: Using the Procrustes-Wasserstein algorithm, we align languages A and C in an unsupervised way. We then build a corpus of queries between the words from language A known from our dictionary and their potential translation into language C. Classical methods proposed the translation that maximized the NN or CSLS criteria. We use deep learning as part of our learning to rank framework to find a more complex criterion. One of the innovative features of our work is, therefore, to allow access to a much larger class of functions for the vocabulary induction stage. A sub-part of the dictionary is used for cross-validation. The way of rating the relevance of the potential translations, the inputs of the algorithm, the loss functions are all parameters that we studied and that are described in the next section.
Prediction: We thus have at the end of the training an algorithm taking as input a vocabulary word, in the form of an embedding and a list of potential translations. Our algorithm’s output is the list sorted according to the learned criteria of these possible translations, the first word corresponding to the most probable translation, and so on. We first perform the alignment of languages A and B using the Procrustes-Wasserstein algorithm again. In a second step, thanks to the learning to rank, we perform the lexicon induction step.
Finally, a final conceptual point is important to raise. In the context of the CSLS criterion, we have seen in the above that its use after alignment has improved. However, actually incorporating it in the alignment phase by modifying the loss function has allowed for greater consistency and a second improvement. However, these two changes were separated. Yet, the learning to rank framework is quite different. The main reason is the non-linearity resulting from deep-learning, unlike CSLS. Therefore, the global optimization is much more complex and does not allow relaxation to get back to a convex case. However, it is an area for improvement to be considered very seriously for future work.
Results
We can split our results into two very distinct parts. They both depend on how the Learning to Rank item sets are built. Given a word, you can build the list of potential traduction from a CSLS criterion and then force or not the right translation presence. This choice needs to be discussed thoroughly. First, let’s quickly present some results with and without the correct prediction forced in the query.
With the forced prediction
Method
EN-ES
ES-EN
EN-FR
FR-EN
Wass. Proc. - NN
77.2
75.6
75.0
72.1
Wass. Proc. - CSLS
79.8
81.8
79.8
78.0
Wass. Proc. - ISF
80.2
80.3
79.6
77.2
Adv. - NN
69.8
71.3
70.4
61.9
Adv. -CSLS
75.7
79.7
77.8
71.2
RCSLS+spectral
83.5
85.7
82.3
84.1
RCSLS
84.1
86.3
83.3
84.1
RUBI
93.3(DE)
91.6(FR)
93.8(NL)
91.9(IT)
EN-DE
DE-EN
EN-RU
RU-EN
Wass. Proc. - NN
66.0
62.9
32.6
48.6
Wass. Proc. - CSLS
69.4
66.4
37.5
50.3
Wass. Proc. - ISF
66.9
64.2
36.9
50.3
Adv. - NN
63.1
59.6
29.1
41.5
Adv. -CSLS
70.1
66.4
37.2
48.1
RCSLS+spectral
78.2
75.8
56.1
66.5
RCSLS
79.1
76.3
57.9
67.2
RUBI
93.6(HU)
89.8(FR)
83.7(HU)
-
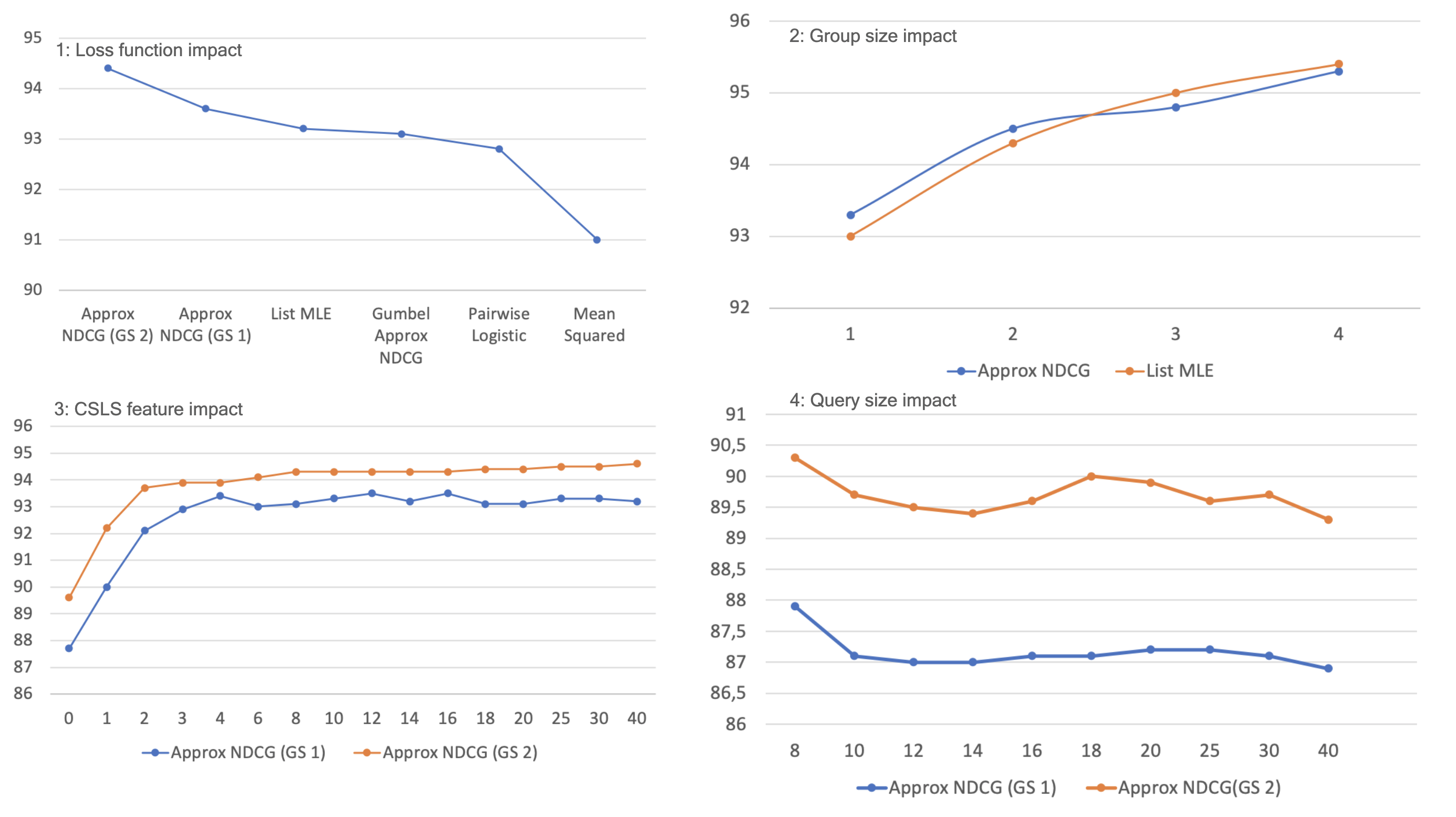
1: Loss function impact - Loss used for the Learning to Rank model. In other experiments, we found that ApproxNDCG and List MLE continue to perform similarly, hence our default choice of Approx NDCG.
2: Group size impact - The group size measures how many items the Learning to Rank model takes as input simultaneously (multivariate vs. univariate). However, the dilemma is to optimize the computation time because increasing the group size exponentially increases the number of calculations.
3: CSLS feature impact - The features for each potential translation in a query can incorporate several elements:
the word embedding of the potential translation (size 300)
the word embedding of the query (size 300)
pre-computed features such as distance to query word in the aligned vector space, CSLS distance, ISF…
Those features are crucial for learning as it will entirely rely on it.
At first, we decided to only use the word embedding of the potential translation and the query. That gave us a 600 feature list. However, after several experiments, we noticed that the learning to rank algorithm, despite the variation of the parameters, could not learn relevant information from these 600 features, the performance was poor. The function learned through deep learning was less efficient than a simple Euclidean distance between the potential translation and the query (NN criterion). In fact, after consulting the literature, we realized that using such a number of features is not very common. Most algorithms were only using pre-computed features (often less than a hundred). Although this information is already interesting in itself, we, therefore, turned to the second approach. We chose to restrict ourselves to certain well-specified types of pre-computed features to evaluate their full impact. More precisely, for a fixed k parameter, we provided as features the euclidean distance to the query and the CSLS(i) “distance” for i ranging from 1 to k. In other words, we provided information about the neighborhood through the penalties described in the section on CSLS.
Training with the full embeddings was also performed but did not lead to any improvements.
4: Query size impact - Number of potential translations given with a query (number of items). There is a low incidence of the number of queries on the results, a very slight but perceptible decrease. Therefore, the algorithm is able, despite a large number of candidates, to discern the correct information.
Plot of the BLI criterion in the training step according to the CSLS criterion, i.e., the quality of the language’s alignment for learning with English. The trend that emerges is that of a very clear positive correlation (linear trend plotted in red, (R ^2 = 0.82)). We have also shown the averages per language family (Romance, Germanic and Uralic). In conclusion, it seems easier to learn using a language that is well-aligned with English. Although this seems logical, it is not that obvious. Three clusters seem to appear in conjunction with the different families. Romance languages are associated with a high rate of alignment with English and, therefore, with high performance in the learning stage.
The Germanic language cluster has a lower performance combined with a slightly lower quality alignment. Knowing that English belongs to the Germanic language type, it is interesting to note this slight underperformance in alignment compared to Romance. Finally, the Slave cluster shows the worst performance in terms of alignment with English and, therefore, also the worst for the learning step.
Without forced prediction
Ablation study for the same pipeline as above, but without the right prediction forced into the query.
Without going into too many details, the same trends as above appear here and hold even when the proper translation is not artificially added to the query.
The main difference comes from the value of the BLI results: we only achieve the same results as the state of the art, or slightly better. We discuss in the conclusion the implication of these results, and especially the importance of forcing the right translation to appear in each query.
Conclusion
If in the Learning to rank framework, a query without at least one relevant item doesn’t have a lot of sense, this is not something one can ensure when working with unsupervised translation. If it is clear that given a query where the correct translation appears, a Learning to Rank model surpasses existing methods, it is still unclear on how to achieve such a query every time. While one way could be to extend the query size drastically, one still has to keep in mind the memory capability of such a model. Another bias might come from every query where the correct translation does not appear naturally (thus always giving poor results to every model except “forced translation” model).
We believe that leveraging the knowledge of previous idioms acquisition can keep leading to many improvements over existing models. This could be achieved thanks to Learning to Rank.
References
1: CHEN, WEI, YAN LIU, TIE, LAN, YANYAN, MING MA, ZHI & LI, HANG 2009 Ranking measures and loss functions in learning to rank. In Advances in Neural Information Processing Systems 22 (ed. Y. Bengio, D. Schuurmans, J. D. Lafferty, C. K. I. Williams & A. Culotta), pp. 315–323. Curran Associates, Inc
2: CAO, ZHE, QIN, TAO, LIU, TIE-YAN, TSAI, MING-FENG & LI, HANG 2007 Learn- ing to rank: From pairwise approach to listwise approach. In Proceedings of the 24th International Conference on Machine Learning, pp. 129–136. New York, NY, USA: ACM.
3: QIN et al. A general approximation framework for direct optimization of information retrieval measures.
4: Ilya Sutskever, Thomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean 2013. Distributed Representations of Words and Phrases and their Compositionality
5: Quentin Berthet, Edouard Grave and Armand Joulin: Unsupervised Alignment of Embeddings with Wasserstein Procrustes, 2018
6: Cédric Villani. Topics in optimal transportation. Number 58. American Mathematical Soc., 2003.
7: David Alvarez-Melis and Tommi Jaakkola. Gromov-wasserstein alignment of word embedding spaces. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018.
8: Mikhail Gromov. Metric structures for Riemannian and non-Riemannian spaces. Springer Science & Business Media, 2007.
9: Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. Advances in neural information processing systems, pp. 2672–2680, 2014.
10: Conneau, A., Lample, G., Ranzato, M., Denoyer, L., and Jégou, H: Word translation without parallel data, 2017
11: Jean Alaux, Edouard Grave, Marco Cuturi and Armand Joulin: Unsupervised hyperaligment for multilingual word embeddings, 2019
12: Georgiana Dinu, Angeliki Lazaridou, and Marco Baroni. Improving zero-shot learning by mitigating the hubness problem. International Conference on Learning Representations, Workshop Track, 2015.
13: Smith, S. L., Turban, D. H., Hamblin, S., and Hammerla, N. Y.: Bilingual word vectors,
orthogonal transformations and the inverted softmax., 2017
This post was made possible by @lastrowview and @Soccermatics which shared the tracking data of 19 goals scored by LFC during 2018–2019 and 2019-2020 seasons.
Our code is available on this GitHub repository.
This article was co-written with Théophane, a classmate, while we worked on this project for a few days.
I now work at Flaneer, feel free to reach out if you are interested!
Sadio Mané, Mohamed Salah and Firmino celebrating.
This post illustrates how data analysis and machine learning can be applied to football players’ tracking data in order to reveal key insights. Our analysis will be articulated in two parts :
Pitch control for opponent analysis
Deep Reinforcement Learning (DRL) for accessing action value
Pitch control for opponent analysis
A pitch control model basically tells you which team is in control of every pitch part at a given time. Here, “in control” means being the quicker to arrive at a specific location in case the ball is shot there.
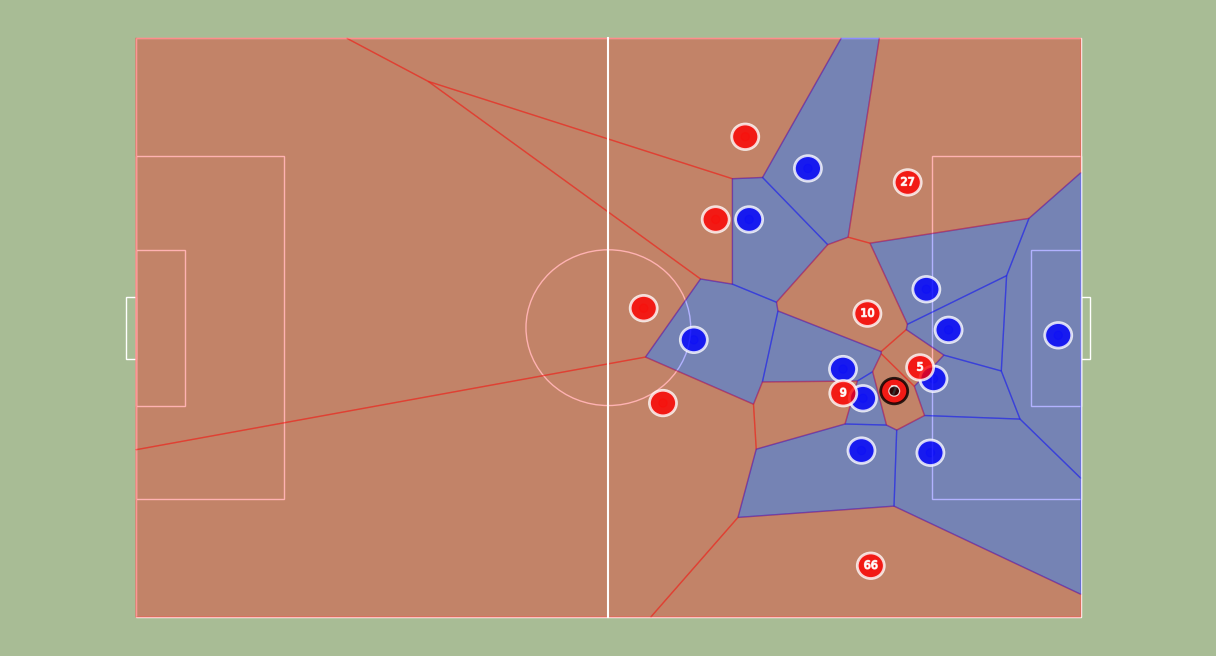
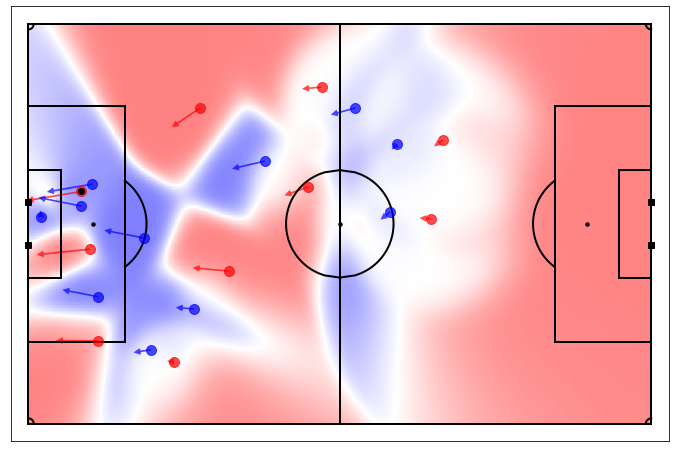
Starting from position data, we got access to speed data thanks to discrete derivation and Savitzky–Golay filter. Then, our approach was to use a time-based Voronoi tessellation operating with ball and players’ tracking data (positions and speeds) as inputs and physical characteristics (player maximum speed, reaction time…) as parameters. This model is an adaptation from the one developed by Laurie Shaw (Harvard) for Metrica’s tracking data.
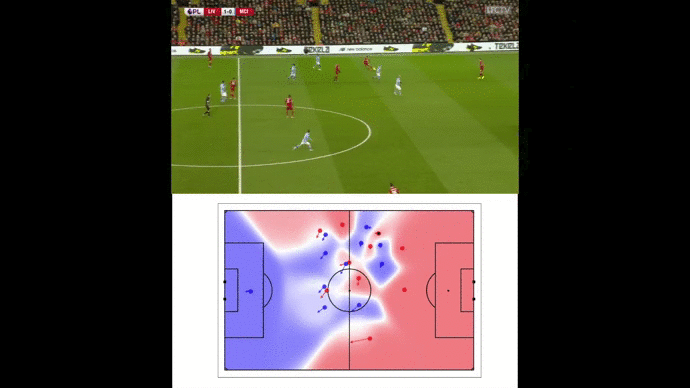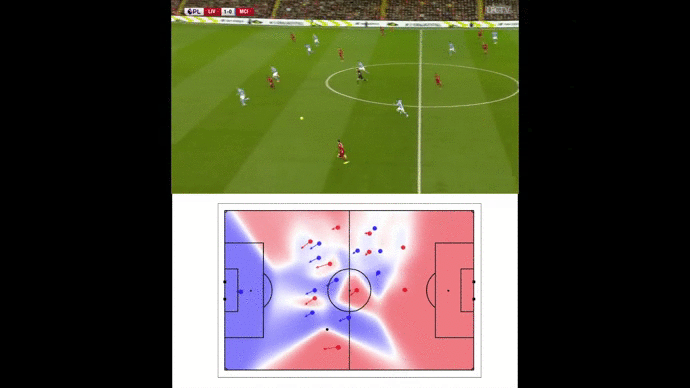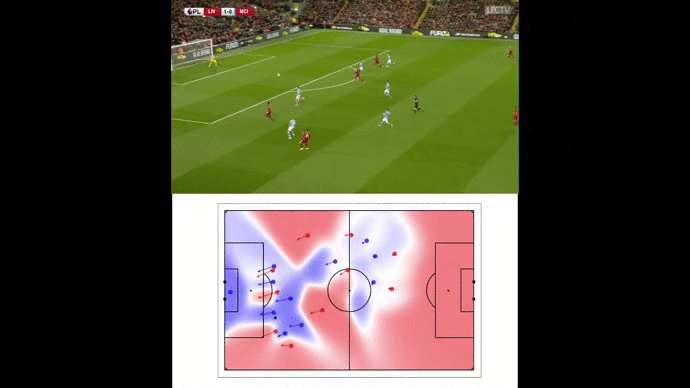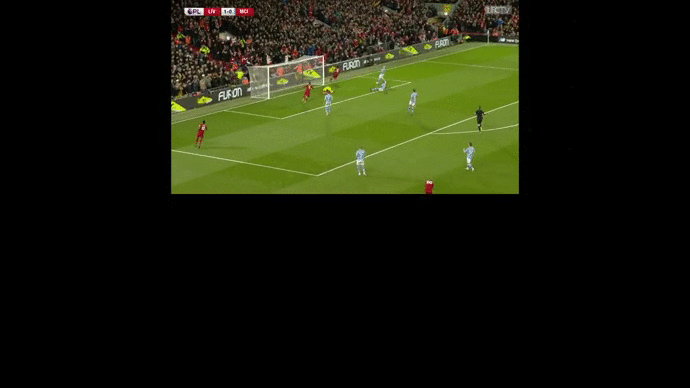
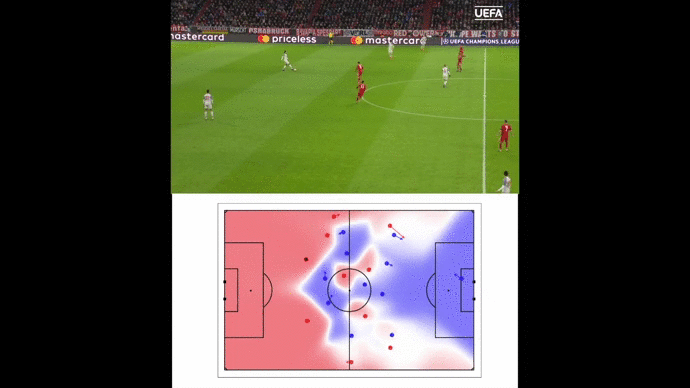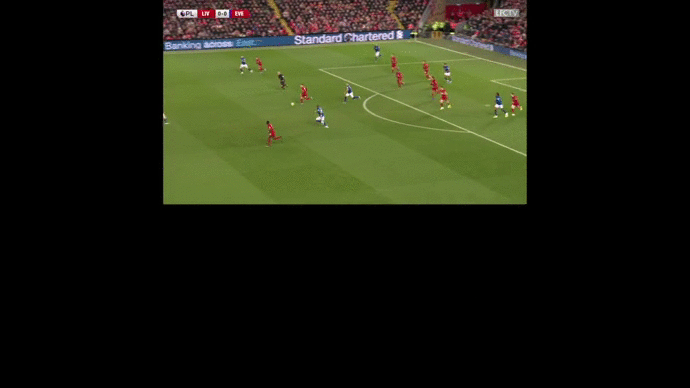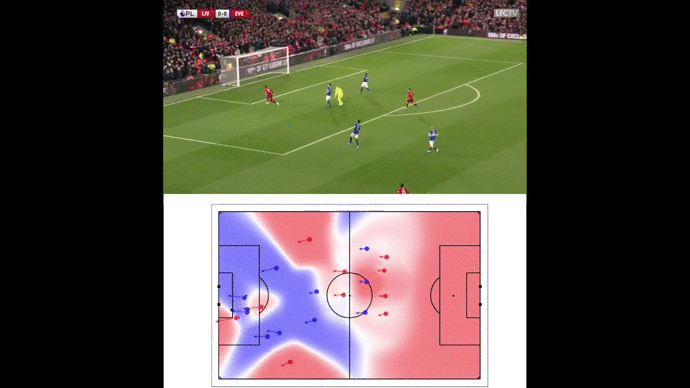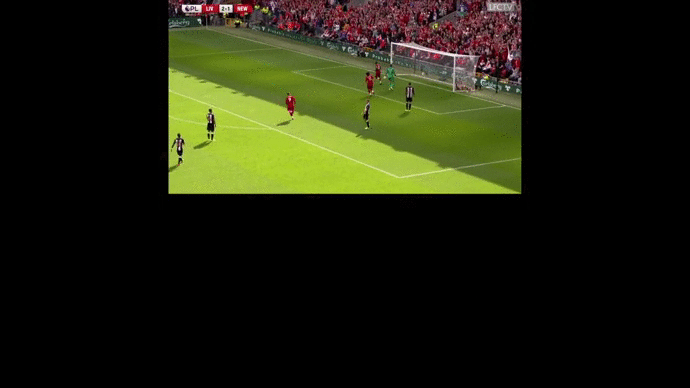
Example of our pitch control output for a given frame extracted from Mohamed Salah’s goal against Manchester City on November 10th, 2019. Liverpool players are in red (of course), Manchester City players are in blue and the ball is the black dot. Arrows represent players’ speeds in meters per second.
After calculating pitch control map frame per frame, we were then able to produce video analysis like this one :
Pitch control analysis of Mohamed Salah’s goal against Manchester City on November 10th, 2019 (assist from Andrew Robertson)
Wing-backs : the two lungs of Liverpool’s attack
Football analysts often emphasize on LFC amazing attacking trio : Mané, Salah and Firmino. In fact, the two wing-backs, Andrew Robertson and Trent Alexander-Arnold, play an offensive role almost as significant as the famous trio.
Analyzing the Reds goals, their attacking system seems to focus on the wings in order to get around the defensive line. Indeed, most of the goals are coming from either curved passes (and crosses) or diving runs from outside to inside.
Our pitch control model enabled us to illustrate space creation by wing-backs such as this triggering run from Alexander-Arnold against Porto FC.
Trent Alexander-Arnold triggers a key diving run to deliver a precise assist against Porto FC in Champions League on April 13th, 2019
This attacking system is based on speed and quick decisions as opposed to more centered playing styles creating a nexus of short passes such as Guardiola’s FC Bayern Munich from 2015–2016 season (or even more in 2010 during Barcelona FC golden age). Therefore, defenders’ response time must be extremely short to counteract the Reds and reach a clean sheet.
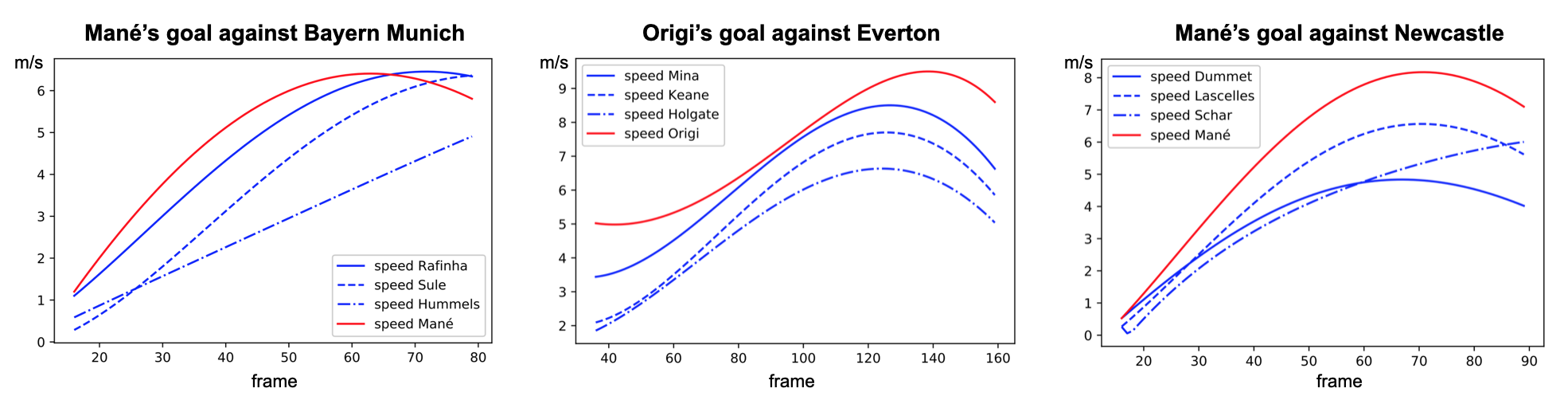
Defenders’ response time : every second is precious against LFC
Comparative analysis of LFC attacking player’s speed evolution versus their direct defenders. Tracking data include 20 frames per second (i.e. 0.05s between each frame)
At first sight, these graphs just seem to show that attacking players are faster than defending players which is not surprising. However, the important point we would like to highlight is the time taken by defenders to reach the attacker’s initial speed. Defenders from Bayern and Everton seem to take a lot more time to react whereas the ones from Newcastle were very reactive (but victim of a huge space between their two center-backs).
The three goals are available here as the support of this analysis.
Same order as the one used for the graph : Bayern Munich, Everton and Newcastle.
This pitch control model enables to produce some insights on the game. Now, let’s see how we can value actions thanks to Deep Reinforcement Learning.
Deep Reinforcement Learning Agent
An important aspect of football analysis is the concept of expected goals (xG). An overview can be found here, with several references as well. We adapt this concept here to the Reinforcement Learning framework, considering a football game as a Markov Decision Process. At its core, reinforcement learning models an agent interacting with an environment and receiving observations and rewards from it. The goal of an agent is to determine the best action in any given state. In the case of football, we could consider :
An episode as one game.
A state as the position and velocity of each player and the ball.
Possible actions as a player moving or making a pass.
The reward as +1 if we score a goal, -1 if we conceded one.
One adaptation of the Reinforcement Learning framework to football can be found here.
A few mathematics considerations
We define a trajectory $\tau$ as a sequence of states and actions experienced by the agent :
\[\tau = \big( s_0, a_0, s_1, a_1, ... \big)\]
and we define the discounted cumulative reward as the gain along a trajectory :
where $\gamma$ is a discount factor, and $r_t$ the reward at time $t$.
Finally, we define the state value function according to a policy $\pi$ (the way the agent behave) as :
\[V^\pi (s) = \underset{\tau \sim \pi}{\mathbb{E}} \big[ R(\tau) \vert s \big]\]
This value function can represent the expected discounted cumulative reward starting from a state $s$ and following a given policy $\pi$. Since, in our framework, we only get a reward when the agent scores a goal, we can interpret $V(s)$ as the expected discounted goals from a given state.
Granted, you would need a policy or an agent that can play the same way the players you are targetting, and that is a complicated issue to tackle. We used here the Google Research Football environment to train our agents and used their hyper-parameters (except for the reward, we used the scoring reward):
We also kept training our agent against middle and hard opponents overtime and finished the training with self-play. We release the checkpoint used for the value function evaluation in our repository.
Finally, we wanted to fine-tune our agent with some Imitation Learning, by using real games data. However, due to the lack of time, this did not happen. It will be the next step for this particular project. We will also need to conduct a more thorough analysis of the differences between this approach and the more usual Expected Goals models. A multi-agent approach might also bring some value to this application, with a more precise prediction of the Expected Discounted Goals.
Results
We convert the tracking data from Last Row into a readable format for our agent :
“The observation is composed of 4 planes of size ‘channel_dimensions’. Its size is then ‘channel_dimensions’x4 (or ‘channel_dimensions’x16 when stacked is True). The first plane P holds the position of players on the left team, P(y,x) is 255 if there is a player at position (x,y), otherwise, its value is 0. The second plane holds in the same way the position of players on the right team. The third plane holds the position of the ball. The last plane holds the active player.” extracted from Google Research Football GitHub
that are stacked for four frames.
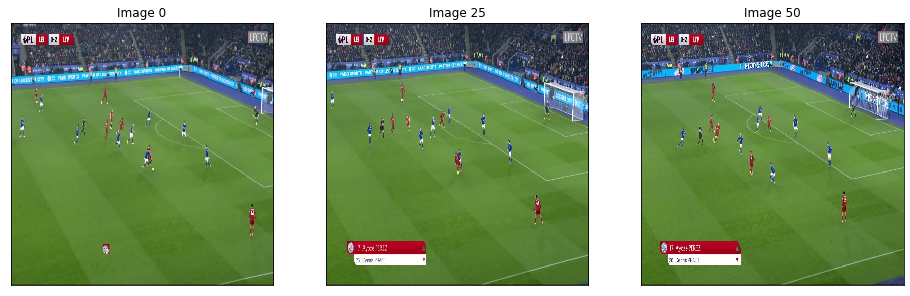
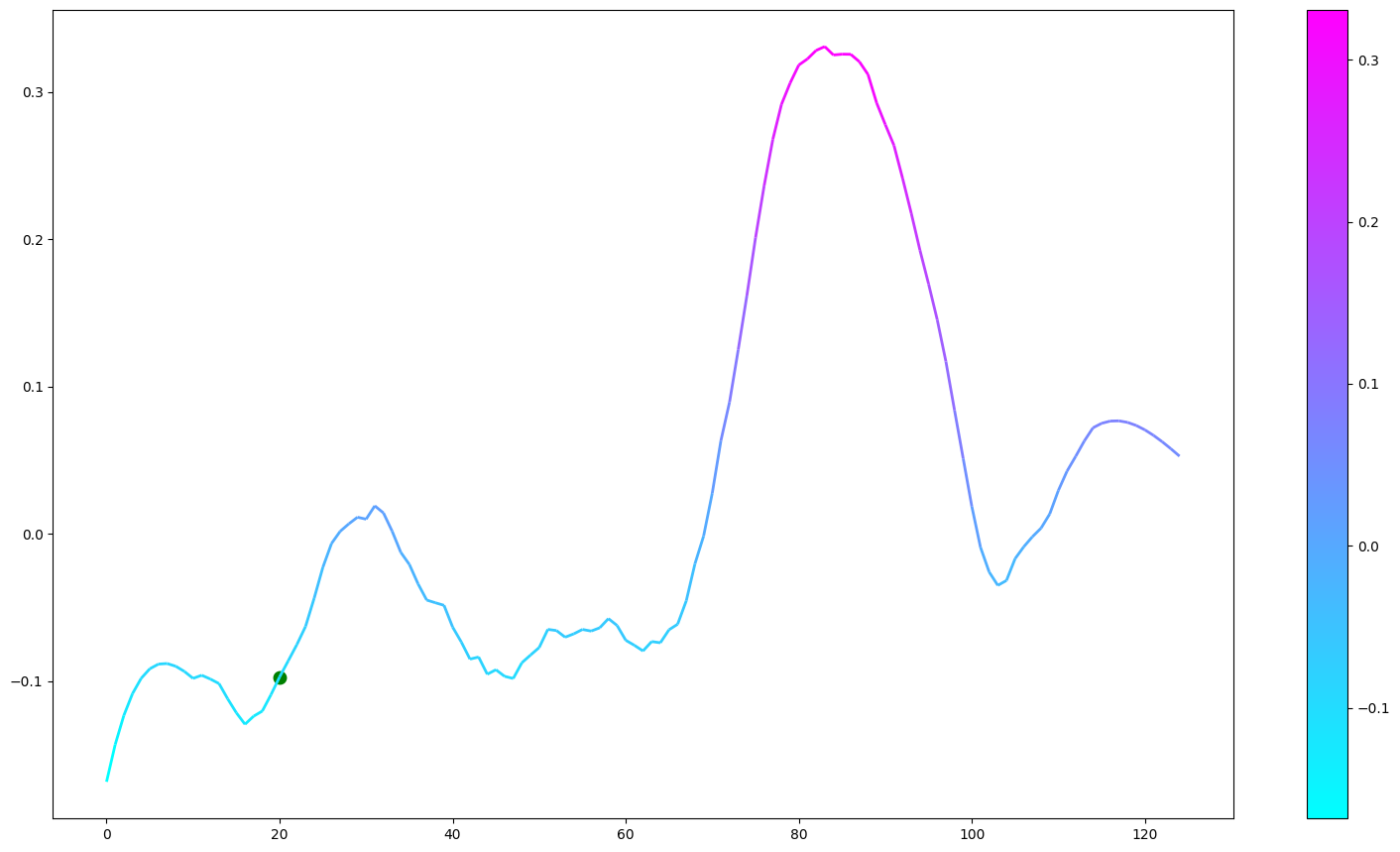
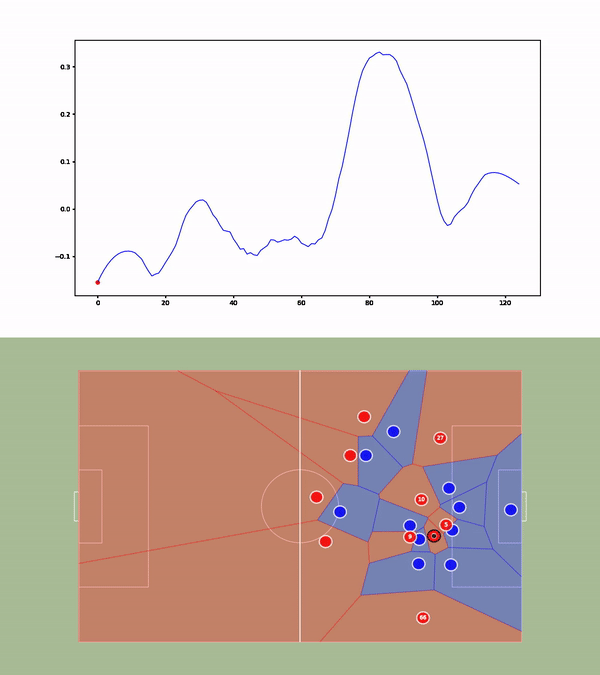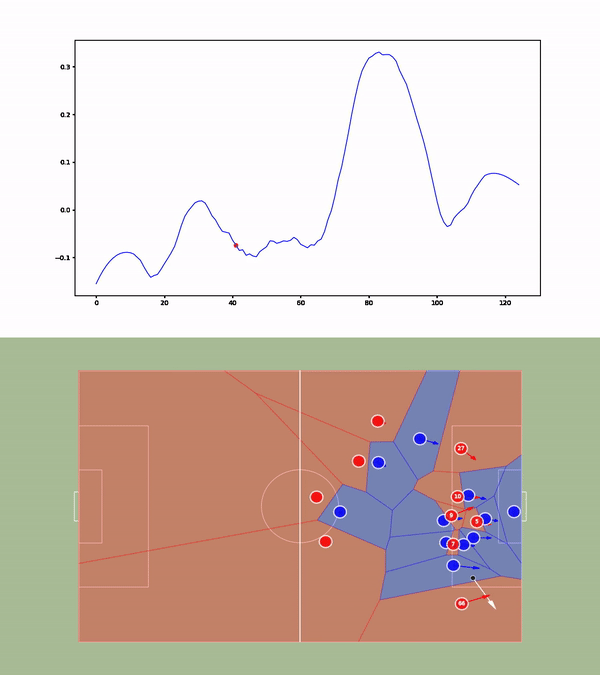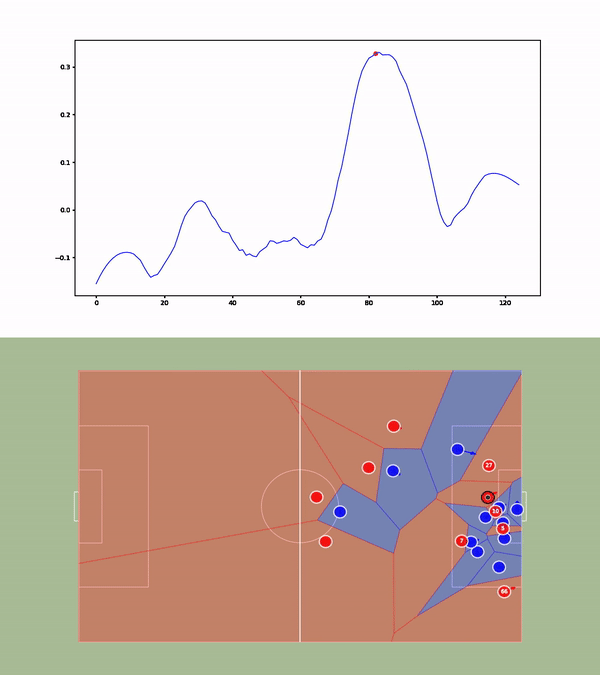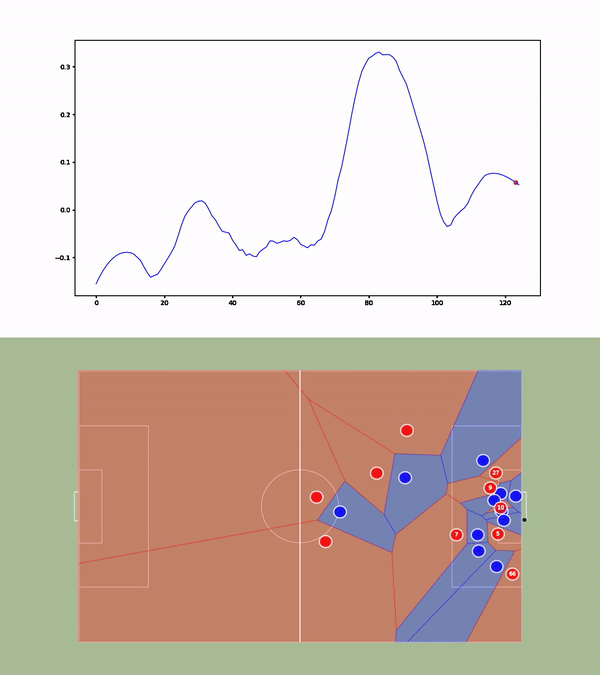
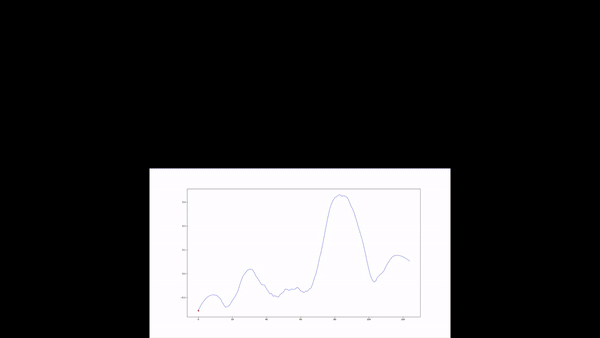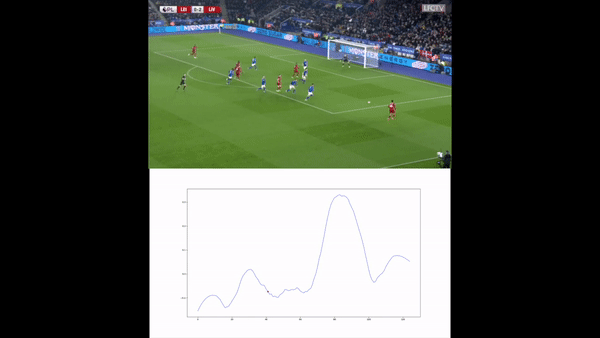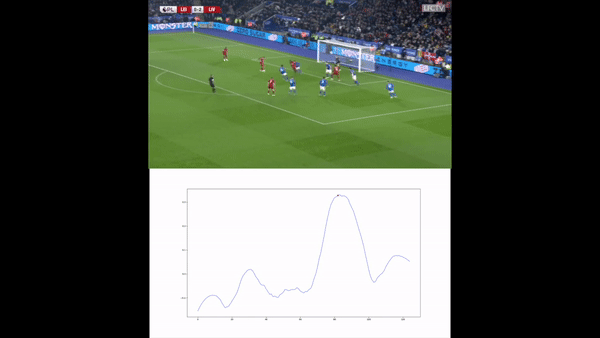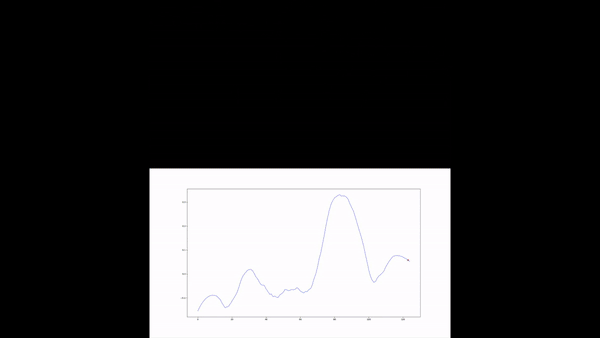
We then compute the value function for each time step and smooth it using a Savitzky-Golay filter. We apply our value function to a goal against Leicester. The results are available below :
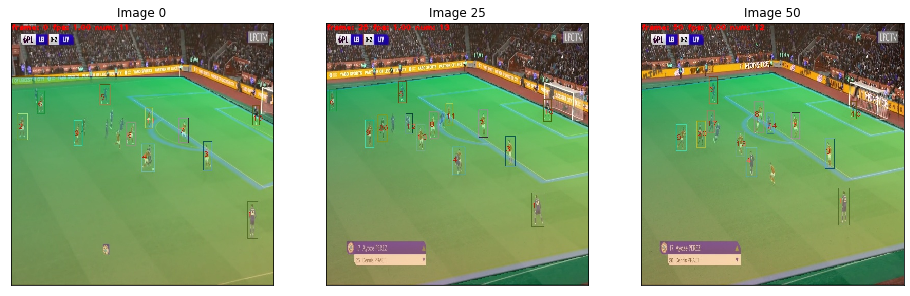
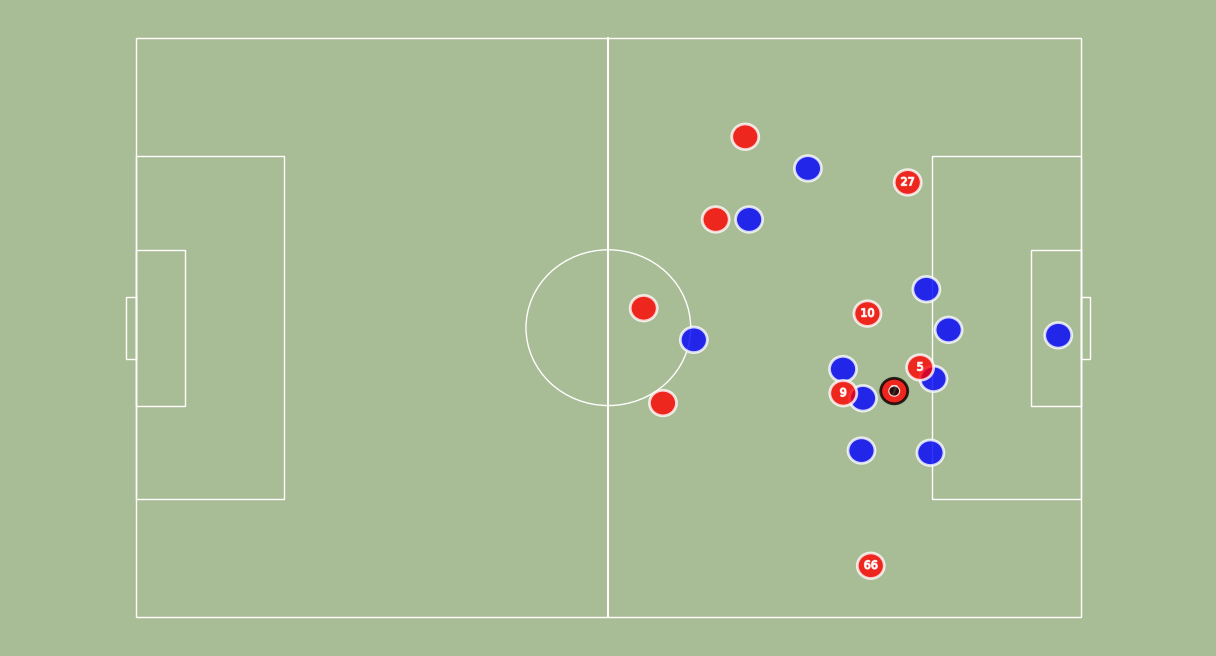
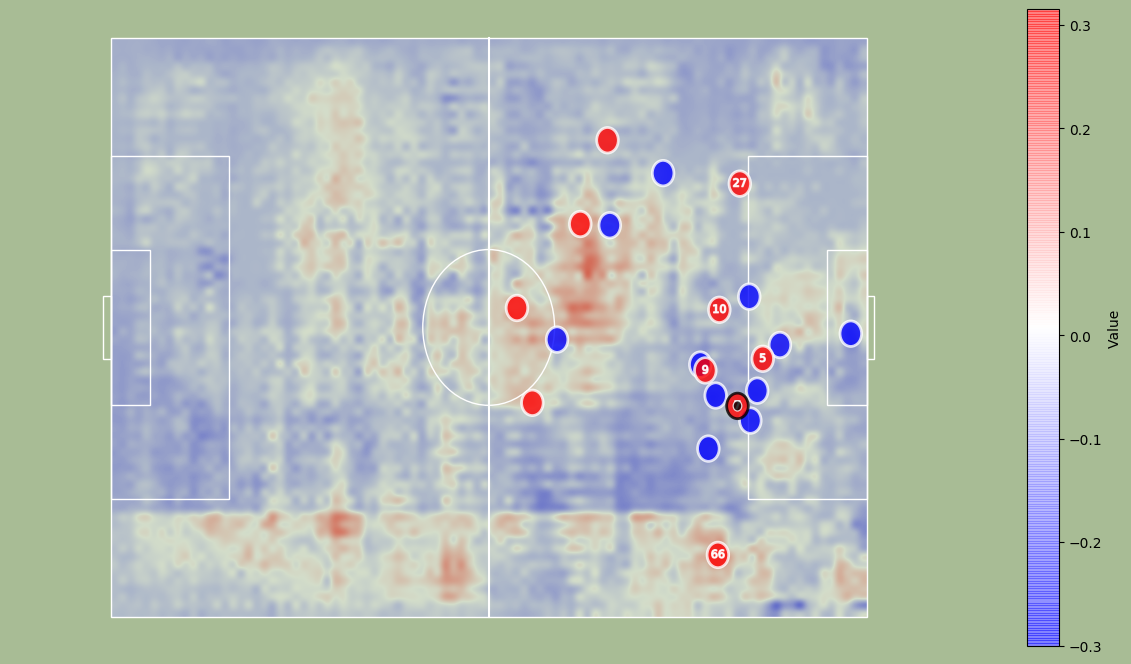
Analyses of a goal against Leicester. We present the value function, and the tracking of the players. A voronoi diagram and the player's velocity vectors are presented as well.
Without over-analyzing the value function, a few things are still interesting to notice :
The pass between time frames 20–30 increases a lot the value function, as well as the assist from Alexander-Arnold.
Overall, the entire action on the right side brings a lot of value.
The value function decreases before the shot (as the agent believes that the action is compromised) and after the goal (since such a configuration is never seen within the simulation)
Analyses of a goal against Leicester. We present the value function, and the real time live goal.
Conclusion
Through this post, we tried to find interesting approaches to Liverpool FC tracking data and we are fully aware our analysis is not complete. We still had a lot of fun working on the dataset provided by @lastrowview and we would also like to thank Friends of Tracking youtube channel for sharing useful repositories and gathering knowledge on Football Data Analysis.
I now work at Flaneer, feel free to reach out if you are interested!
When we started talking about this project with Matthias and then Arthur, we knew that both building a Lego motorized car, and learning to drive with real-life Deep Reinforcement Learning was possible. However, we wanted to do both at the same time. We also wanted to try another approach: Imitation Learning. We recently acquired a Raspberry Pi 4b and knew that the power limitations set by the previous model vanished. However, we didn’t know exactly how to fit everything into a lego car, and how to train it properly. We came up with 2 vehicles and used 2 methods of learning :
a first model (that looks terrible), driving with a Deep Reinforcement Learning Agent
a much better-looking car, driving with an Imitation Learning algorithm
The first car we built, not the best looking...
The Pi-Mobile V2, based on a Lego Technic Porsche Model
The first one drove on an inside track built in my home, while the second drove outside.
PI-Mobile V1
Assembling the car
The first step of building a lego car is building its structure and deciding the location of each component in the car to make it as compact as possible. We started by building each block and then assembled them. It resulted in a working car, but not in the fastest nor best-looking one.
The structure
We decided to choose a 3-engines solution: two at the back of the car that power each wheel separately, and one at the front powering the steering system that we built.
From top left to bottom right : Lego Mindstorm cables, RaspberyPi 4b + BrickPi, 8 AA batteries, RasbperryPi 3b + Lithium battery + fan, 2 Large Lego Mindstorm motors, 1 Medium Lego Mindstorm rotor
We chose to separate the car’s electronic system in two halves: one half is the core of the vehicle and will be linked to the motors, powering them, and will take care of the DRL part of the project. The second half is down the first part, as all the operations listed above are energy-consuming.
The core part consists of a Raspberry Pi 4b (we chose this device to be the center of all the operations because of its vast specifications compared to the Raspberry Pi 3b) and a card from Dexter Industries that manages the link with the lego technics. In contrast, the second part consists of a battery powering a Raspberry Pi 3 that powers a small fan, installed in between the two cards of the car’s core. While using a Raspberry Pi 3 to power a fan seems a bit of an overkill; it also allows us convenient a flexibility in programming, were we to decide to use a Master/slave architecture to compute the DRL part if the RP4 capped its power due to overheating.
We then used a raspbian image, unaltered, with the convenient package VNC Viewer, which allows us to access the raspbian of the PI via SSH protocol. From there, we can launch our script to make the car move.
We also used a raspberry camera on top of the car. This camera was the only input our car would use to drive around.
The track
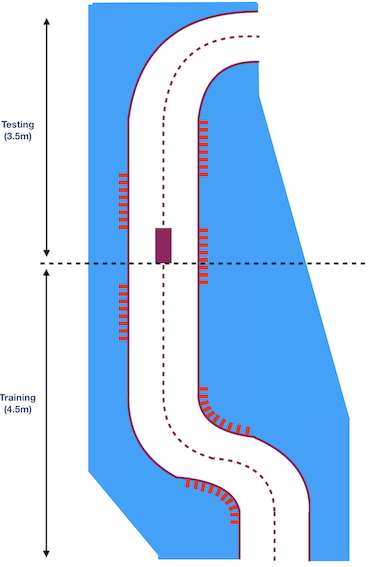
The PI-Mobile V1 trained on a track we built inside my house. It is made of paper and is 8 meters long. However, it has a bridge in the middle, a bridge the car could never learn to pass properly (it struggled to go only forward because of a faulty steering system). Because of this, we split the track into 2 parts: a training part and a testing part :
The learning algorithm - DQL
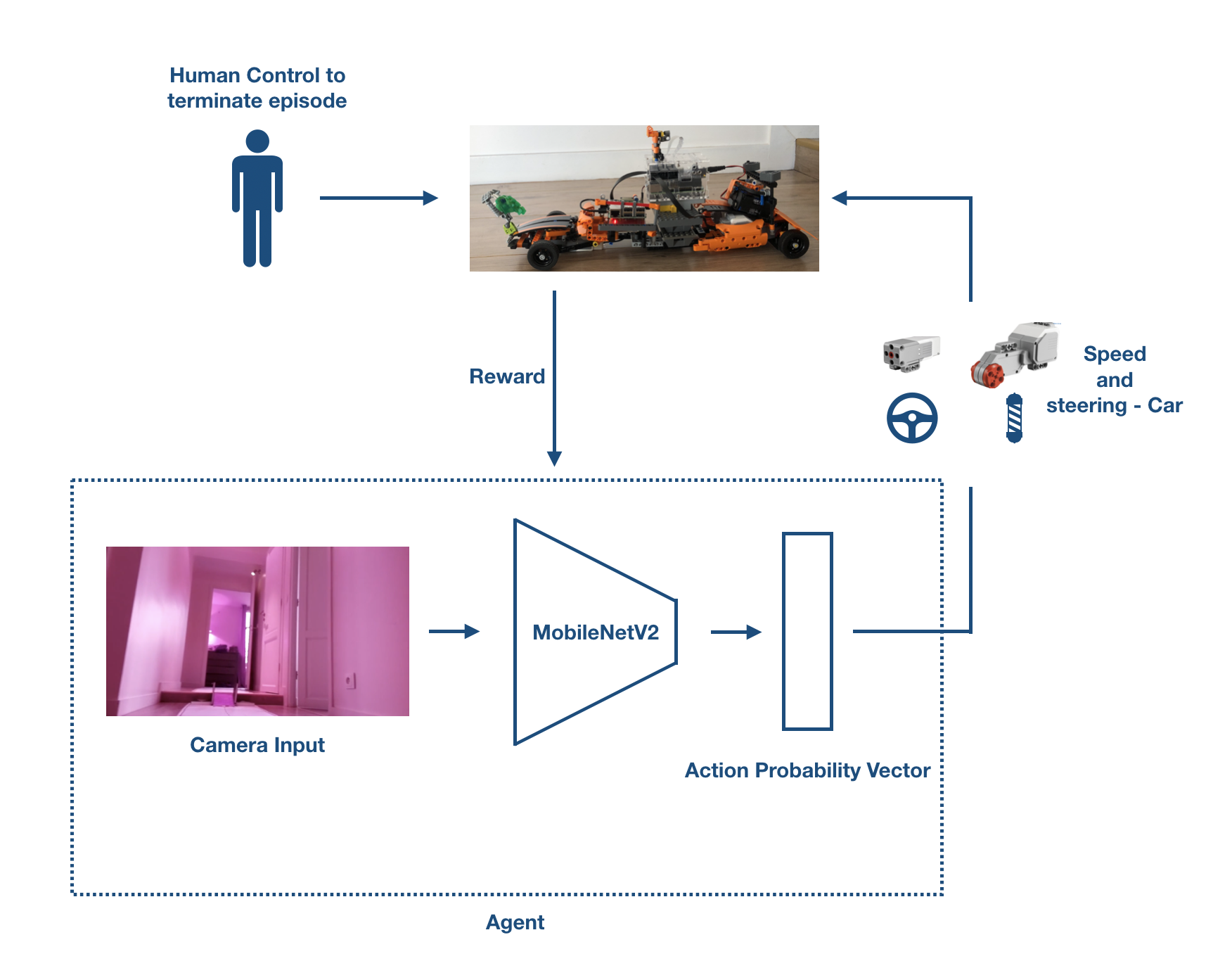
We used a Deep Q-learning agent to train our car to drive, with some minor modifications: human control. Since the agent is not interacting with a simulation but with the real world, we are the one telling it when to stop, or when it’s good or bad. We set up several keys: one to pause the current episode, one to finish it when the car is doing something bad, and finally, one to end the episode when the car reaches the end of the track. The algorithm is available below :
Regarding the reward, we used a simple function: 1 at every step, except when the car fails (-1) or when it reaches the end of the trach (time spent on the track). The goal is to drive correctly and as fast as it could.
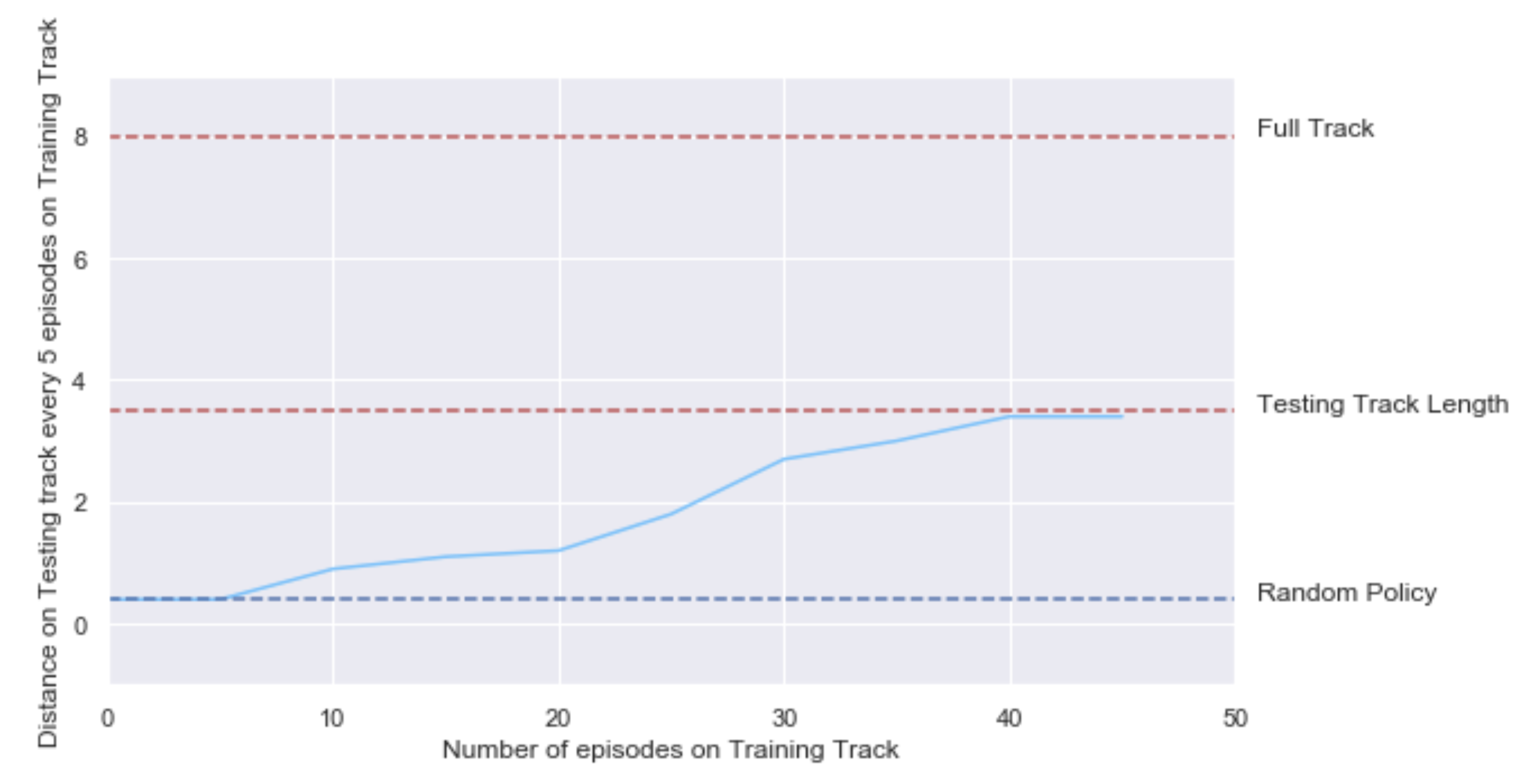
Overall, our car learned to drive on the testing track in less than 50 episodes (around an hour and a half). We tracked the distance made autonomously on the testing track every 5 training episodes :
Distance autonomously driven by the car on the testing track
An example of a training episode is available below :
PI-Mobile V2
Now that we knew that our car could learn to drive on its own, we wanted to make some modifications:
Car V1
Modifications
Car's structure was not robust enough
Started from an existing Lego Technic car
The fan system was taking a lot of place
Remove the fan and the Raspberry 3
The DRL agent was not necessarily the best solution
Use of an Imitation Learning algorithm
The track was too small
Train the car on a bigger track outside
Structure
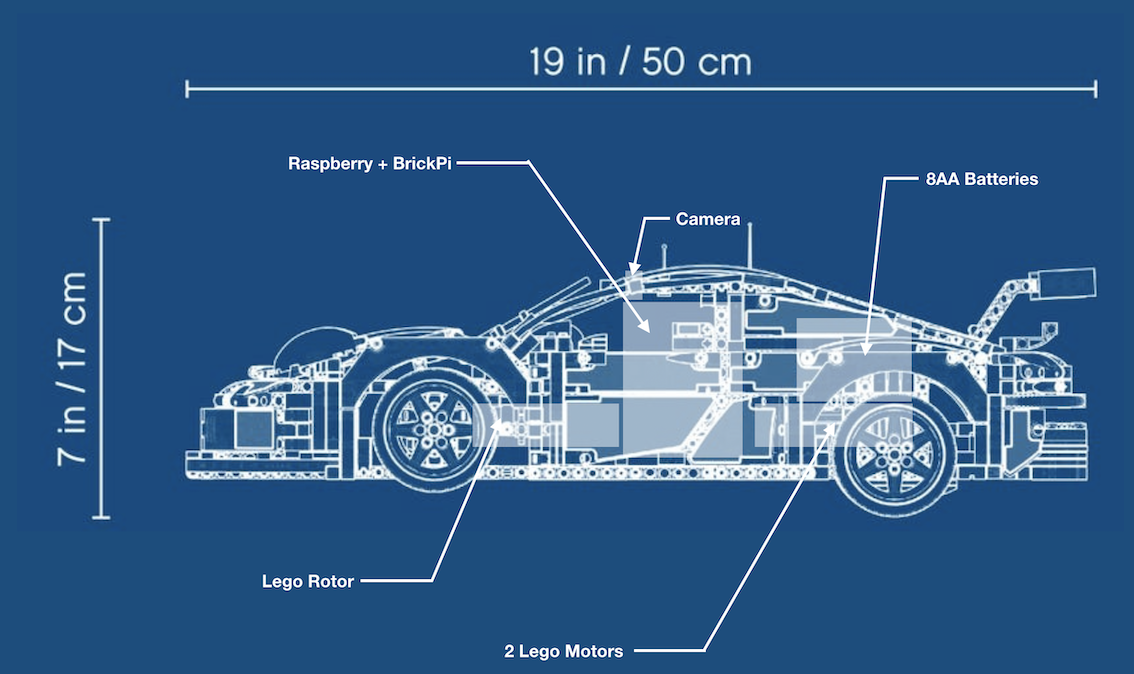
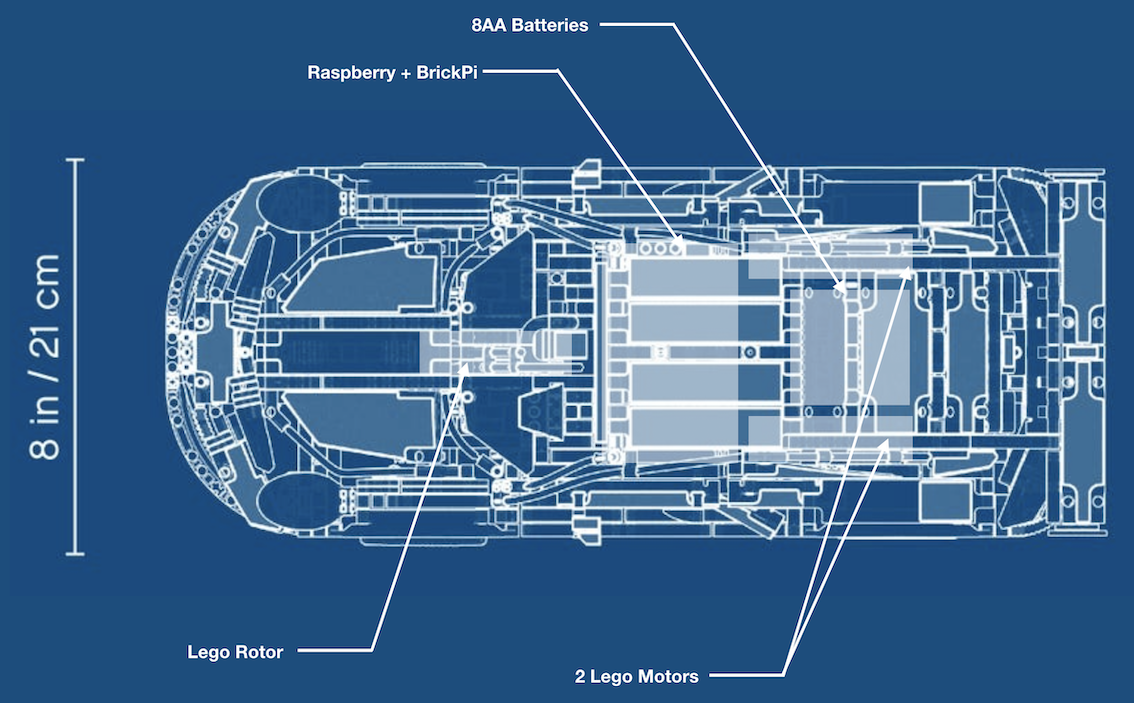
We kept the same main pieces (Raspberry Pi 4, BrickPi, and 3 motors) but changed the rest of the car. We used a Lego Technic Porsche 911 model as a base for the rest of the car.
Our goal was to use the following blueprint :
However, we had to make some modifications, mainly because of 2 things:
The suspension system at the back of the car was not compatible with our Large motors
The case used for the Raspberry Pi + BrickPi was not made for a Raspberry Pi 4, and therefore was not as robust as it should have been.
We removed the V6 engine and replaced it by the Raspberry Pi and the batteries. We also made some modifications to insert the Lego Rotor at the front, and the 2 Lego motors at the back. Using this as a baseline allows the car to be much more stable and with a more precise steering system. The first version also tended to break in the middle of the chassis; this doesn’t happen anymore.
Chassis of the PI-Mobile V2, with the 2 motors and the Raspberry Pi/BrickPi in the middle.
The track
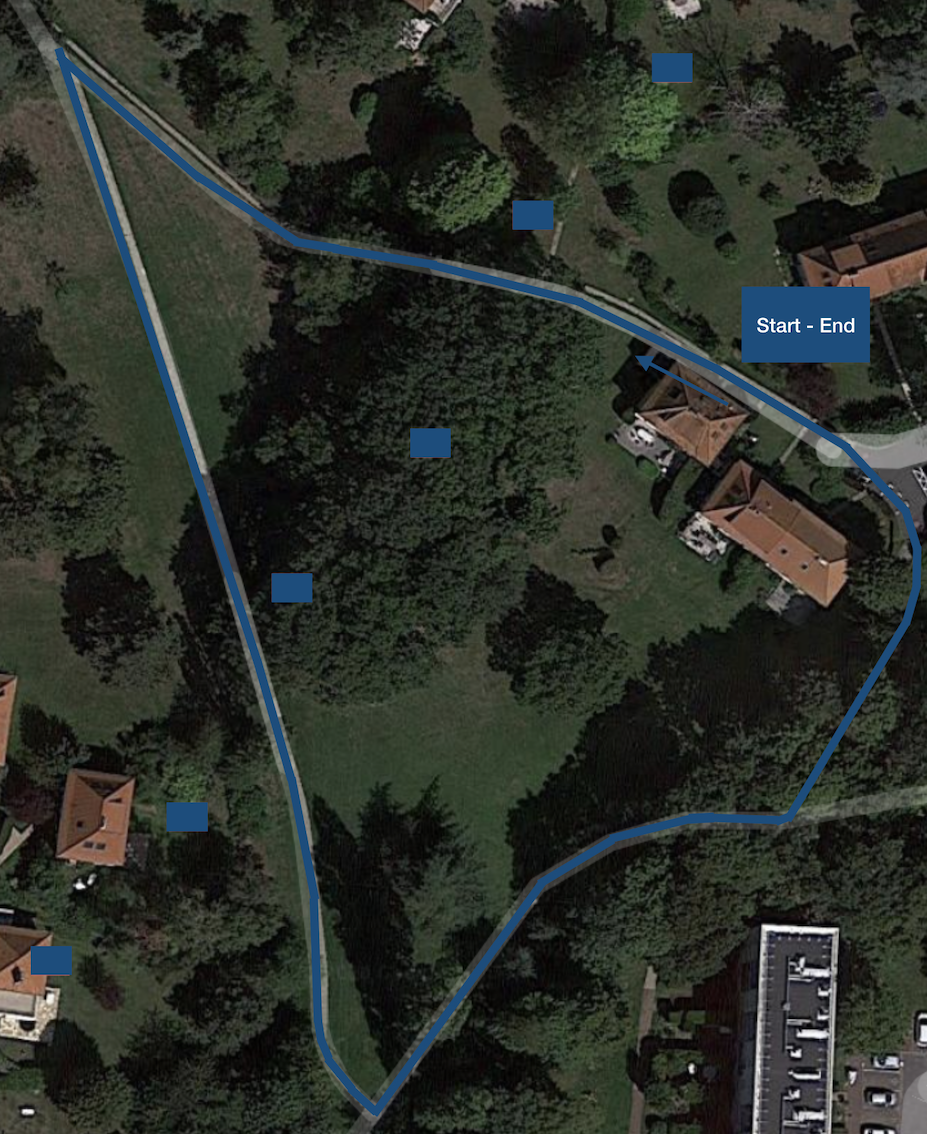
We wanted to be a bit more ambitious and step aside from the small inside track we used for the first car. We used a short pathway around the house as a circuit. This pathway lies inside a large garden, making it easy to define where the vehicle should drive and make a loop: precisely what we needed.
Track used to gather data for the PI-Mobile V2. Track is around 400 meters long.
We would then use the rest of the pathway for testing our model. An example of such a pathway is available below :
Example of the road used for the second track
Now that we have a new car and a new track, it is time to talk about the models we used to make our car autonomous.
Imitation Learning and Conditional Imitation Learning
Imitation Learning
Let $\mathcal{O}$ be the set of possible observations. In our case, it is the input from our camera. Let $\mathcal{A}$ the set of possible actions, here it could be turn left or right or go straight. Let’s suppose we have a dataset $\mathcal{D}$ made of observation-action pairs $(o_i,a_i)$, collected from our driving, for example.
The idea behind Imitation Learning is to learn a policy $\pi$ mapping observations to actions, $\pi _{\theta} : \mathcal{O} \rightarrow \mathcal{A}$. The policy would allow the car to know which actions to perform depending on the observation: the camera input, according to the driving we’ve done before.
The policy can then be trained by minimizing the distance between the policy $\pi _{\theta} (o_t)$ and the expert’s actions $a_t$. However, in some cases, the expert’s action is not enough. For example, our car might have the possibility to turn left or right in some cases, and we need to tell it what it should do: this is Conditional Imitation Learning.
Conditional Imitation Learning
The framework is the same as above, but we add a command $c_t$, expressing the expert’s intent when the policy is predicting an action to do. The mapping now takes the following form : $\pi _ {\theta} (o_t, c_t)$. The minimization process changes to
Let’s now dive into the model we used and the dataset we collected :
Model & Dataset
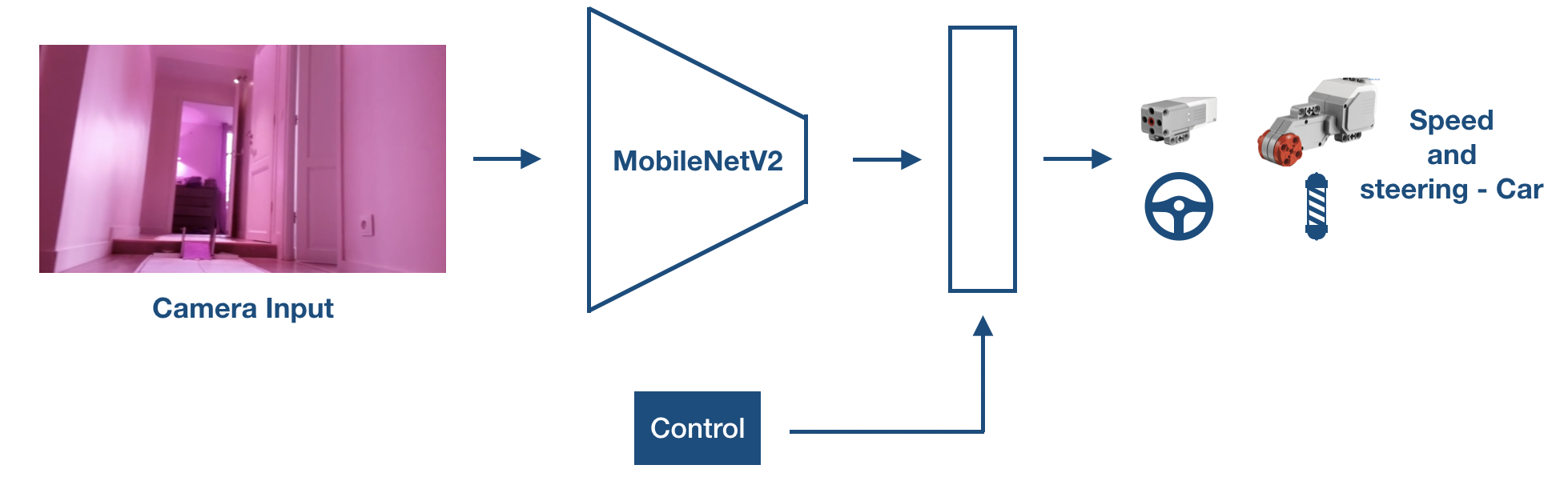
Model
We kept the same neural network base, with a MobileNetV2 pretrained on ImageNet:
Dataset
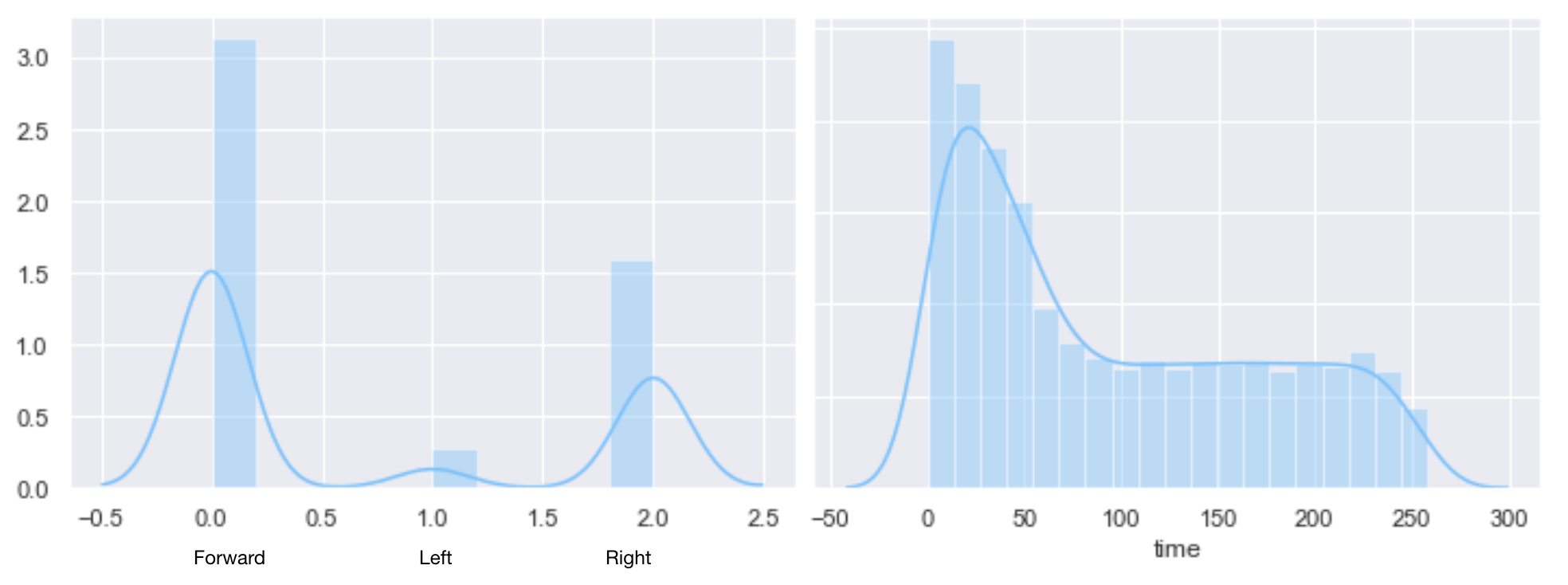
We drove the car for around 15 minutes on the track, gathering around 9000 frames with inputs and controls (the controls were added by hand afterward when 2 decisions were possible). We used 5000 frames for the training, 2000 for the validation, and 2000 for testing. However, because of another steering issue, the car was naturally going to the left when we were inputting a forward command. Therefore, most of the driving consisted of inputting forward and right to make sure the right would stay on track. Because of this, only a few left inputs were issued, mostly for significant turns. This can be seen below. We also split the dataset into smaller episodes to make sure that the Raspberry stoping itself would not delete a file too large.
Distribution of the input and timestamp on the dataset
We trained the model twice: once without data augmentation and once by including it. The data augmentation consisted of adding some random modifications regarding:
Brightness
Small rotation
Small height and width translations
The model without data augmentation gave poor results, especially during our first test session, where the time of day and weather were completely different. This emphasizes the fact that the training dataset must generalize to real-world testing: different weather, different lighting and different road style. This data augmentations made the car going from a complete failure to an acceptable robot.
Overall, we should have made a better dataset, mainly making sure we had no steering issues. This made the testing difficult, forcing us to add artificial left steering and to make the car starts with the same proper angle as in the dataset.
Results
Nevertheless, we achieved good results with the augmented dataset. The predictions made by the model on the testing dataset are available below :
We also tested the car on another portion of the track, although with similar weather conditions from the training dataset :
Self driving car V2, some outside modifications were made to make an easier access to the RaspberryPi and the batteries.
Conclusion :
Overall, it was an extremely fun project to do, and more importantly, did not require a lot of sophisticated knowledge. The car can be built with Legos, the motor, and the BrickPi from Dexter Industry is easy to use with Python. Furthermore, the Deep Learning algorithms we used can be found anywhere. It was actually exciting to see how we could put every “tech brick” one after another, and end up with a working self-driving car. Granted, following a track and making a few turns is far away from the demanding needs of a real autonomous car, interacting with others, but the basics of driving can still be learned with simple components.