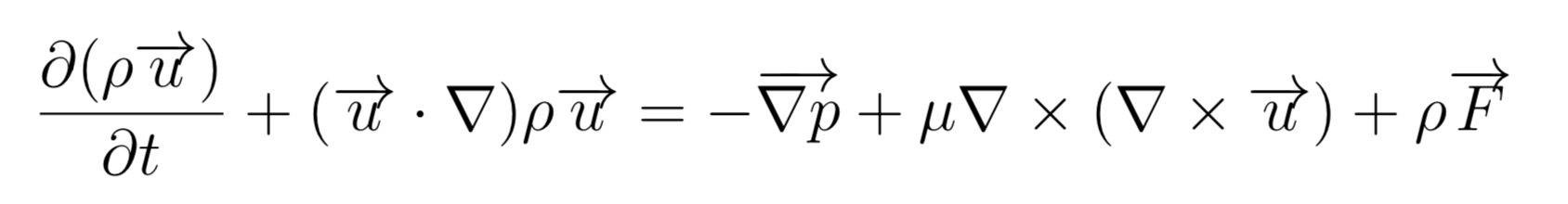I now work at Flaneer, feel free to reach out if you are interested!
When I started an Internship at the CEMEF, I’ve already worked with both Deep Reinforcement Learning (DRL) and Fluid Mechanics, but never used one with the other. I knew that several people already went down that lane, some where even currently working at the CEMEF when I arrived. However, I (and my tutor Elie Hachem) still had several questions/goals on my mind :
How was DRL applied to Fluid Mechanics?
To improve in both subject, I wanted to try a test case on my own;
How could we code something as general as possible?
The results of these questions are available here, with the help of a fantastic team.
Applications of DRL to Fluid mechanics
Several Fluid Mechanics problems have already been tackled with the help of DRL. They always (mostly) follow the same pattern, using DRL tools on one side (such as Gym, Tensorforce or stables-baselines, etc) and Computational Fluid Dynamics (CFD) on the other (Fenics, Openfoam, etc).
Currently, most of the reviewed cases always consider objects (a cylinder, a square, a fish, etc.) in a 2D/3D fluid. The DRL agent will then be able to perform several tasks :
Move the object
Change the geometry or size of the object
Change the fluid directly
A small step into the world of fluid mechanics
The Navier-Stokes equation looks pretty (and complicated) but is in fact traduction of Newton's equation for a fluid. Rather than describing the movement of an object, it is representing the movement of a fluid (more precisely, of a field (of points, vectors, etc).).
This equation is quite a paradox itself. Its application are enormous, but we still don't know if solutions always exists (it is even one of the seven Millenium Prize Problems).
Solving the Navier-Stokes now doesn't mean we are trying to solve it. We use the finite element method to 'slice' our domain into small parts, and starting from initial conditions, we run our simulation, making sure our equations are 'approximatively verified' every (little) timestep.
This agent can perform these tasks at two key moments : (i) when the experiment is done, and you want to start a new one, (ii) during the experiment (i.e., during the CFD time). One is about direct optimization; the other one is about continuous control. A few examples can be seen below :
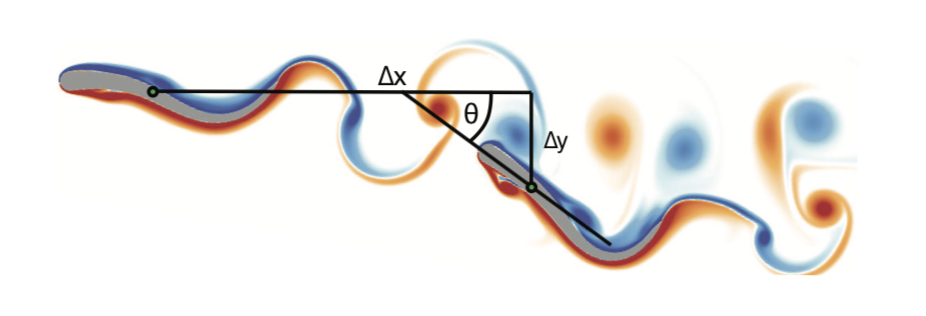
Leader and Follower swimmer reproduced from Novati et al. (2017), with the displacement and the orientation between the leader and the follower.
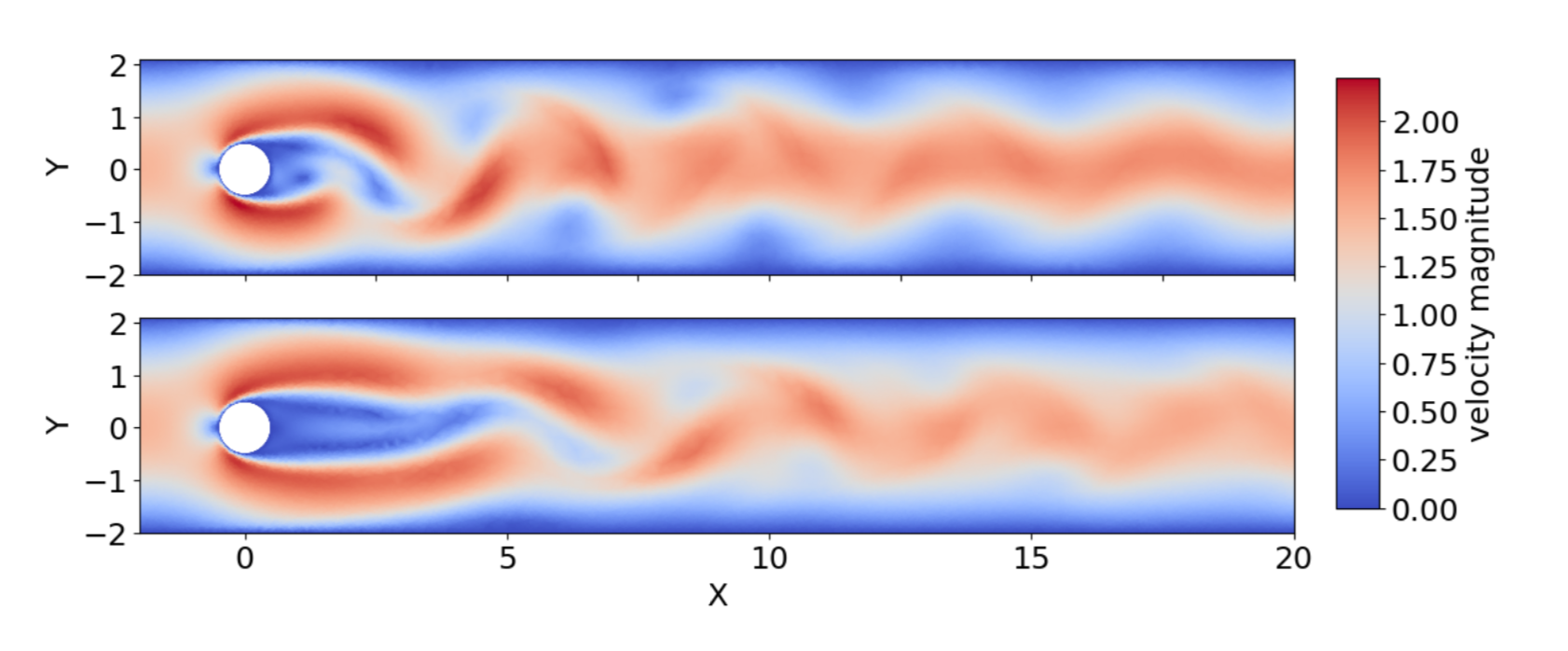
Comparison of the velocity magnitude without (top) and with (bottom) active flow control, reproduced from Rabault et al. (2019). This active flow control being linked to a DRL agent.
Fluid jets to control rigid body reproduced from Ma et al. (2018). The position and orientation of the jet are DRL controlled.
In order to dive deeper into the subject, I wanted to try a test case on my own (with the help of Jonathan Viquerat at the beginning though). We took inspiration from this paper and considered a simple case: a laminar flow past a square. Now, it is convenient to compute the drag of this square (in this very set-up).
However, the question asked by the paper was: if we add a tiny cylinder, somewhere close to the square, could we be able to reduce the total drag of both the square and the small cylinder?
The answer is yes, and the result is shown below:
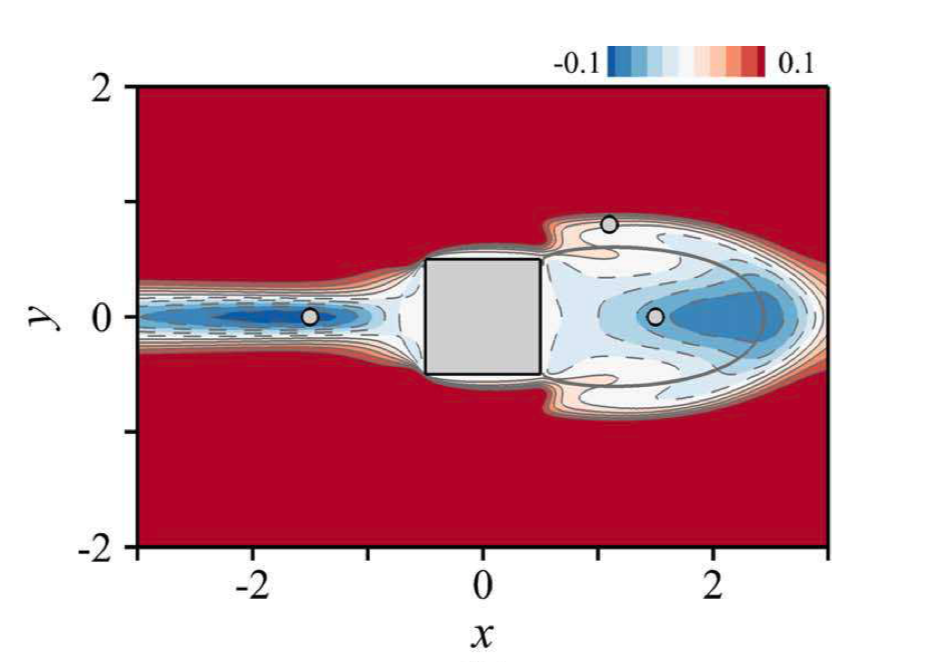
Variation of drag induced by a small control cylinder at Reynolds = 100, reproduced from Meliga et al. (2014).
Now, of course solving this case with DRL was interesting, but I wanted to see if more was possible (since the case was already settled technically). Several ideas were possible (thanks to discussions with peoples from the CEMEF and the review I did previously) :
Was there any difference between direct optimization and continuous control?
Was the use of an autoencoder easy?
Was Transfer Learning possible, and performant?
Could we make a code as clear as possible?
Regarding the first point, I found no particular difference between direct optimization and continuous control. Both agents converge and find almost the same optimal final positions.
Continuous control over 17 time-steps at Reynolds = 40 and 100, from two random positions.
I used an autoencoder but had no time no compare results with and without it. I do have to explain why an autoencoder could be of any help here. The agent needs observations, and when dealing with fluid mechanics, the fluid characteristics are significant observations.
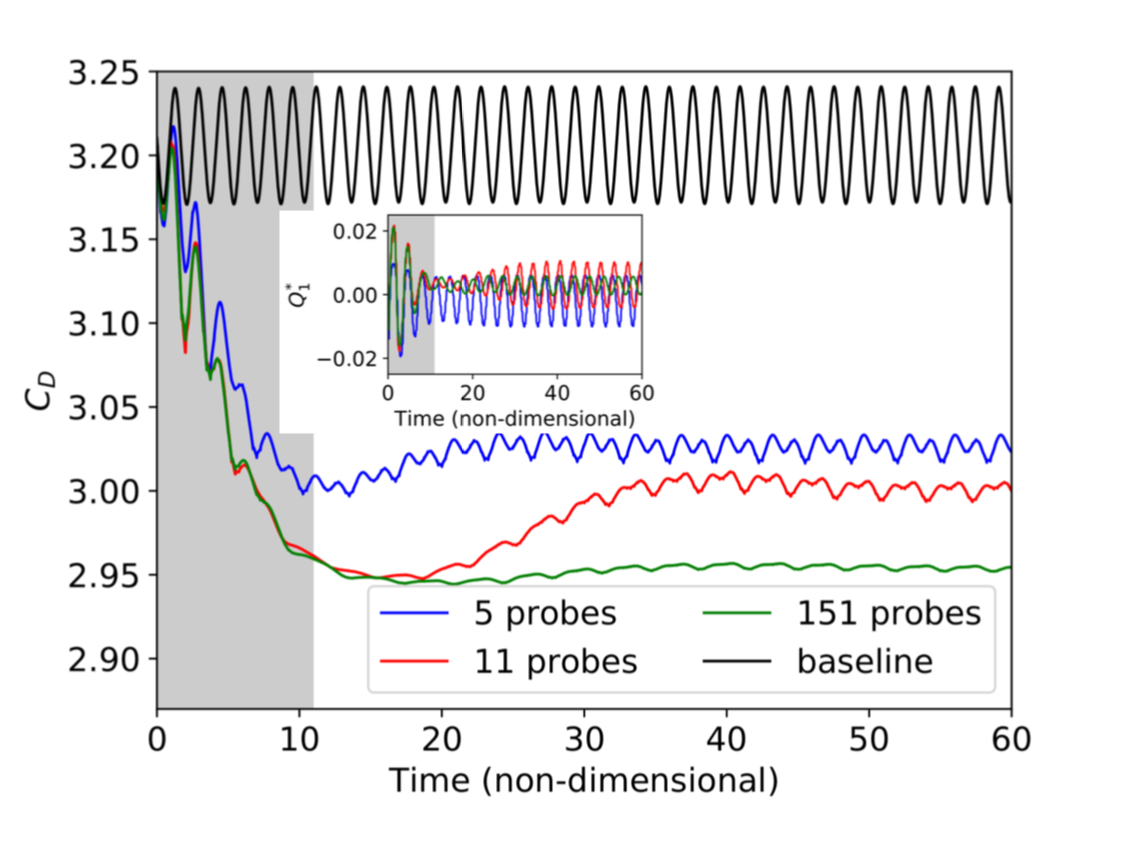
However, they can be of very high dimensions (more than 10,000). The Neural Network (NN) we would deal with would then be incredibly vast. In order to surpass this issue, an autoencoder could be used to extract simple features from high-dimensional fluid fields. It does seem like using as many fluid features as possible (which is possible with the autoencoder) is the best thing to do:
Value of the drag coefficient with active flow control reproduced from Rabault et al. (2019). It is important to see that the more pieces of information we give about the fluid (i.e., the more probes we give the agent), the more performant it will be. Being able to give everything without exploding the size of the neural network is therefore super valuable.
In total, I trained six agents, as shown below :
Agent
Reynolds Number - Re
Goal
Details
Agent 3.2
Re=100
Direct optimization
Transfer learning from Agent 1.2
Agent 1.1
Re=10
Continuous control
Trained from scratch
Agent 1.2
Re=10
Direct optimization
Trained from scratch
Agent 2.1
Re=40
Continuous control
Transfer learning from Agent 1.1
Agent 2.2
Re=40
Direct optimization
Transfer learning from Agent 1.2
Agent 3.1
Re=100
Continuous control
Transfer learning from Agent 1.1
As you can see, I used transfer learning and obtained excellent results from it: the agent was learning from 5 to 10 times faster than the agent trained from scratch. This is an exciting feature in general, but especially for Fluid Dynamics, where CFD is computationally expensive.
A DRL-fluid mechanics library?
At the beginning, my goal was to find out if such a library could be built (in a reasonable amount of time). During the creation of my test case, I realized the biggest issue with such a library was coming from the CFD solver: not only no one is using the same, but they all are pretty different.
For my test case, I based my code on Fenics, an easy-to-use solver (and super convenient since you can use it directly in Python). The code is available here. It is supposed to be as clear and re-usable as possible. It is based on Gym and stable-baselines.
I used Gym to build custom environment, always following the same pattern :
With stable-baselines, I used their DRL algorithms implementations, and finally, as I said earlier, I used Fenics to build my test case using custom class that I hope will be re-used for other test cases. They use three main class: Channel, Obstacles, and Problem :
Channel :
Basically, this is the box you want your experiment to take place in. You only define it by giving the lower and upper corner of the box.
classChannel:"""
Object computing where our problem will take place.
At the moment, we restraint ourself to the easier domain possible : a rectangle.
:min_bounds: (tuple (x_min,y_min)) The lower corner of the domain
:max_bounds: (tuple (x_max,y_max)) The upper corner of the domain
:Channel: (Channel) Where the simulation will take place
"""def__init__(self,min_bounds,max_bounds,type='Rectangle'):
Obstacles :
This is the objects you want to add to the previously seen box. If you only want to use Fenics, you can only easily add squares, circles, or polygons. However, if you want to add much more complex shapes and mesh, you can use the Mesh function from Fenics.
classObstacles:"""
These are the obstacles we will add to our domain.
You can add as much as you want.
At the moment, we only take care of squares and circles and polygons
:size_obstacles: (int) The amount of obstacle you wanna add
:coords: (python list) List of tuples, according to 'fenics_utils.py : add_obstacle'
:Obstacles: (Obstacles) An Obstacles object containing every shape we wanna add to our domain
"""def__init__(self,size_obstacles=0,coords=[]):
Problem :
This is where everything is taking place: setting up the box, placing the several objects, defining the boundary conditions, etc.
classProblem:def__init__(self,min_bounds,max_bounds,import_mesh_path=None,types='Rectangle',size_obstacles=0,coords_obstacle=[],size_mesh=64,cfl=5,final_time=20,meshname='mesh_',filename='img_',**kwargs):"""
We build here a problem Object, that is to say our simulation.
:min_bounds: (tuple (x_min,y_min)) The lower corner of the domain
:max_bounds: (tuple (x_max,y_max)) The upper corner of the domain
:import:import_mesh_path: (String) If you want to import a problem from a mesh, and not built it with mshr
:types: (String) Forced to Rectangle at the moment
:size_obstacle: (int) The amount of shape you wanna add to your domain
:coords_obstacle: (tuple) the parameters for the shape creation
:size_mesh: (int) Size of the mesh you wanna create
:cfl: (int)
:final_time: (int) Length of your simulation
:mesh_name: (String) Name of the file you wanna save your mesh in
:filename: (String) Name of the file you wanna save the imgs in
"""
However, this is not getting even close to a true DRL-fluid mechanics library, the issue being Fenics. While being very easy to use, it is a slow solver, and it would be impracticable to use it for a challenging problem. This is why, with other people working at the CEMEF, the goal is to build this library, linking DRL with other CFD libraries, most of them being C++ based.
In the end, we now have a better overview of how DRL can be used to help Fluid Mechanics problems. Moreover, several important features can be kept in mind: transfer learning, autoencoder, LSTM, and so on. If the goal of building a real DRL-CFD library was not achieved, the way it could be possible is now much clearer.
I now work at Flaneer, feel free to reach out if you are interested!
Codingame is a website where you can solve puzzles, work on optimization problems, and build bots for games. You have access to a vast range of codding languages, and I personally mainly used Java, Python & C++.
What I enjoy the most is to build AI for multiplayer games: a card game, a quidditch match, a Tron battle, etc.
A quidditch game from Codingame where your AI controls 2 players. This is a great game that includes great AI and physics.
A game inspired from Star Wars where you control 2 pods. You can learn a lot about several algorithms: genetic algorithms, MCTS, min-max, etc.
Legends of Code & Magic (LOCAM)
The game
This is a game created by Jakub Kowalski and Radosław Miernik, in cooperation with Codingame. This is a card game, opposing two players. The game is turn-based, zero-sum, and without a possibility to tie. It is important to note that you only have 100ms to play each turn. The game is separated into two parts :
First, you have to draw 30 cards from a pool of 160 cards. During 30 turns, the game will propose you three cards, and you have to choose the one you want to pick.
After that, each player will play. I can do several actions: summon a creature, attack the opponent, use an item, etc.
The game will end whenever someone’s hp drop to zero.
Overview of the game, with both players HP, mana, cards in hand and cards on the board.
The rules
We can split the game into several components: Drawings, Mana, Creatures, and Items.
Drawings: The first player starts with four cards, while the opponent begins with five. Each turn you will draw a new one (some of them might even allow you to draw several cards at the same time).
Mana: You can only use a card if you have enough mana. Both players start with one Mana and gain one for every turn they play.
Creatures: Creatures have a mana cost, attack points, and defense points. Some creatures start with specific abilities. By default, creatures can’t attack the turn they are summoned, and they can attack only once per turn. When a creature attacks another one, they both deal damage equals to their attack to the defense of the other creature. When a creature attacks the opponent, it deals damage equals to its attack to the HP of the opponent.
Items: When played, items have an immediate and permanent effect on the board or the players. They can modify the attack or defense of a creature, add or remove abilities. They can also damage or heal the opponent or yourself. You can find three types of items: green items (positive effect on your creatures), red items (harmful effect on the opponent’s creatures) and blue items (effects on yourself or the opponent directly).
As for the six special abilities :
One of the strongest card in Legends of Code & Magic, with the six different abilities.
Breakthrough: Creatures with Breakthrough can deal extra damage to the opponent when they attack enemy creatures. If their attack is higher than the defending creature’s defense, the excess damage is dealt to the opponent.
Charge: Creatures with Charge can attack the turn they are summoned.
Ward: Creatures with Ward ignore once the next damage they would receive from any source. The “shield” given by the Ward ability is then lost.
Lethal: Creatures with Lethal kill the creatures they deal damage to.
Guard: Enemy creatures must attack creatures with Guard first.
Drain: Creatures with Drain heal the player of the amount of the damage they deal (when attacking only).
My bot
My bot was split into several parts. The first one was dealing with the Drafting phase. It was a simple heuristic with a score for each card. The second part was dealing with the summoning phase, while the last one dealt with the attacking phase. I built both of them with variants of Monte-Carlo methods and Monte-Carlo Tree Search.
You only have a limited amount of time when you play :
Actions
Allocated time
Response time per turn
100ms
Response time for the first draft turn
1000ms
Response time for the first battle turn
1000ms
Monte Carlo
Intuitively, a Monte-Carlo method means that we will use several random draws to approximate the value of something. It could mean: shooting random arrows in a square with a circle in it. The proportion of arrows into the circle will allow us to approximate $\pi$. In a game, we could simulate random moves and evaluate them to find the best sequence of move possible.
On a more mathematical point of view, let $x_1, x_2, …, x_N$ be i.i.d. laws, following the same law as a random variable $X$. For any borelian fuction $f$ (with $f(X) \in L^1$), we can calculate the following approximation :
In fact, if we denote $I = \mathbb{E}(f(X))$ and $I_N = \frac{1}{N} \displaystyle \sum_{i=1}^{N} f(x_i)$, we have thanks to the strong law of large number :
\[I_N \rightarrow I \; \; a.s.\]
For example, let’s say we are playing a game of tic-tac-toe. Every time we have to play, one solution could be to perform several random moves, evaluate them (which one is the most promising?) and play the best. Even more, we could also play several sequences of random moves (e.g.,: one move for me - one for my opponent - one for me) and apply the same strategy.
MCTS
Now, a Monte-Carlo method has several flaws, but one of them is the fact the moves are drawn randomly. We could spend a lot of time simulating moves that are not interesting at all. Therefore, an idea would be to simulate and evaluate the more promising moves. This is called a Monte-Carlo Tree Search.
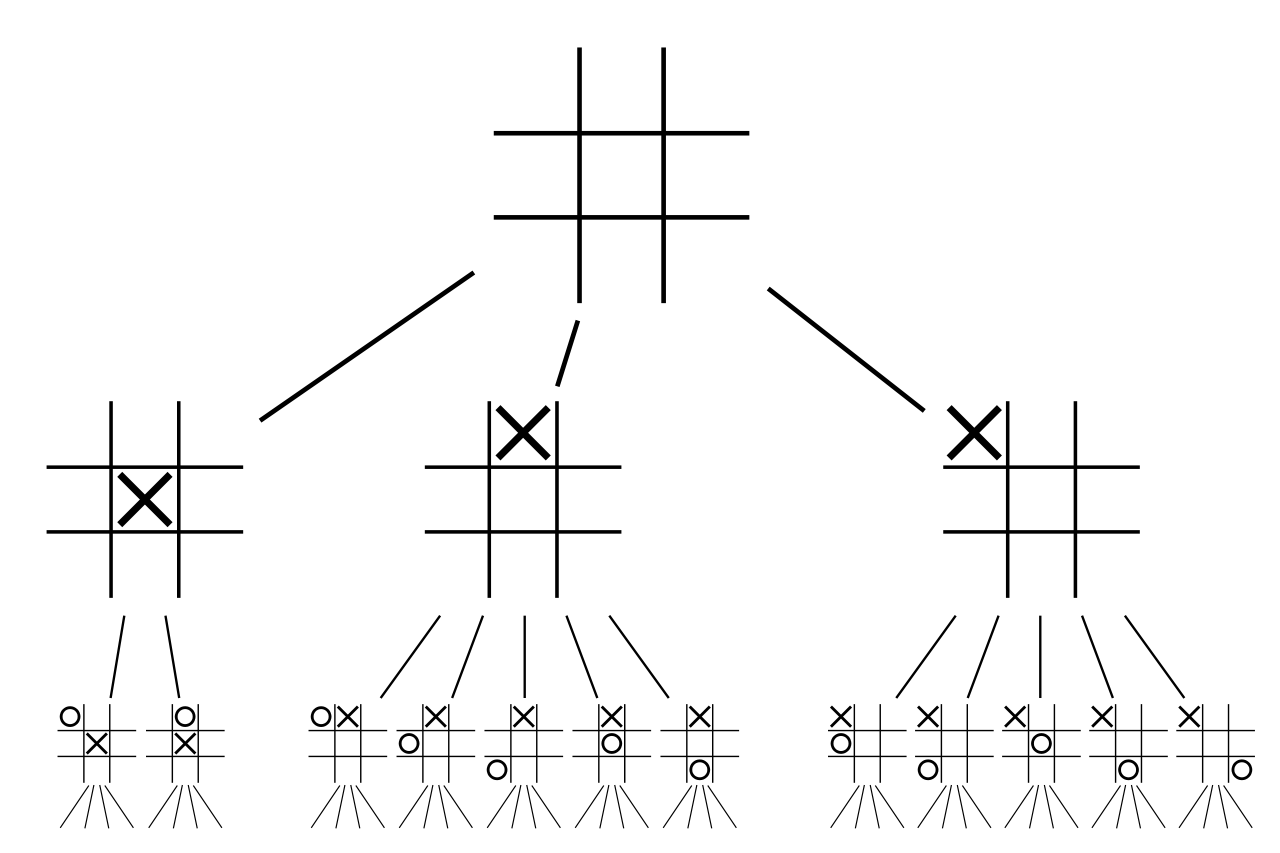
The first idea is to view a game as a tree: each node being one possible state of the game.
Trees
A tree is a mathematical/CS object with powerful properties. The best way to see it is to consider how one is built :
Each tree starts with a particular node: the root
Each node has several sons
Each nodes (except the root) has unique father
A tree is a great and understandable way to store informations. A very vast theory also exists around it: how to run trough one, etc.
An overview of the beginning of a tic-tac-toe game, reproduced from
Medium
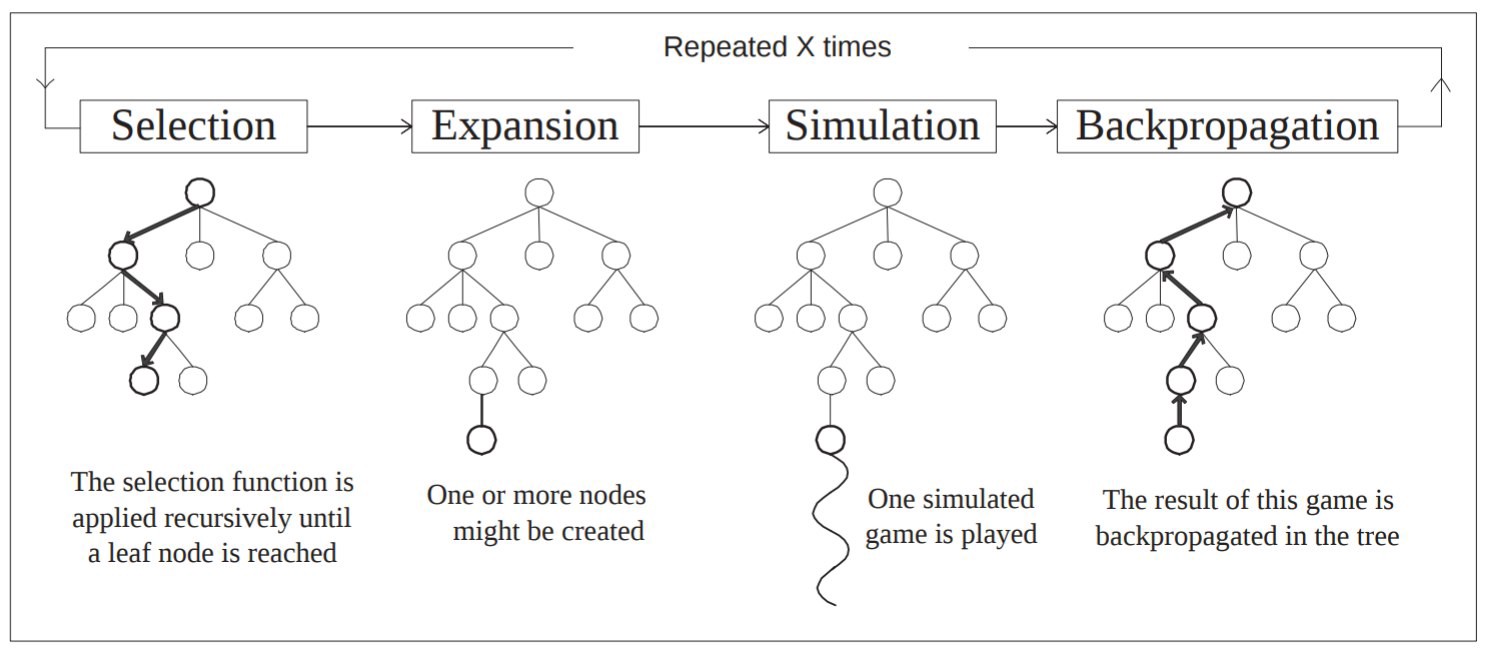
An MCTS always follows the same four steps:
Selection
Starting from the root, we select childrens, often following the UCT formula (the node maximizing the following):
\[\frac{w}{n} + c\sqrt{\frac{\ln{N}}{n}}\]
where $w$ is the amount of win from this node, $n$ the amount of time we visited this node, $N$ the amount of time we visited this node’s father and $c$ an exploration parameter. This formula is supposed to give a good comprise between exploration and exploitation.
Expansion
If the selected node isn’t terminal, we simulate one child from it.
Simulation
We simulate a game, starting from this child until we reach a terminal state.
Backpropagation
Since we reached a terminal state, we can update every visited node with the new information: we lost, or we won.
An MCTS supposes that it is possible (in a reasonable amount of time) to reach a terminal state. Now, this might not be possible: only partial observations (like in this game, where you can’t predict the hand of the opponent), computational time that is too heavy, etc. Therefore, it is interesting to define an evaluation function (like in Evolutianory Algorithm): the goal of such a function is to characterize how good (or bad) a state of the game is.
For example in a game of tic-tac-toe, it could be the number of opportunity (square that would make you win if you played here)
Draft phase
When the contest started, I believed that the draft phase would not be the crucial part of the contest. As it will turn out, this was a mistake. My first strategy was to follow a mana curve (a sort of gaussian, with a mean at 6 of mana). If this strategy worked fine at first, this was not the best choice.
After some talks with other coders from the contest, the idea of hardcoding a score for each card emerged. The plan would then be to draw the card with the higher score. The real question was: how to compute such scores? The strategy I used was to build genetic algorithms; each individual of the population being a set of scores for each card.
Genetic Algorithms
To keep things as simple as possible, a genetic algorithm starts with a population made of a fixed number of individuals. At every generation, you compute the score of each individual, and then keep some of the best for the next generation.
To build the rest of this next generation, several options are available: mutations, melting two existing solutions, tournament to keep some of them, etc.
This is an optimization algorithm I love, and I used it a lot on Codingame.
Overview of a Genetic Algorithm. The part with different implementations can use tournament, random selections, full crossover or only mutations of the best individuals.
In order to evaluate each individual, I used several methods. All of them are based on the same strategy: playing many games with this draft against another fixed one, and keeping the win rate as the score of the individuals.
In the end, this method gave me a score for each card, score I kept until the end of the contest.
It seemed like a good idea, and it turned out it was. However, some other players went further, with varying scores depending on the deck you already had, and achieved even better results.
Playing phase
A key point here, since as I said earlier, it is impossible to simulate the game until a terminal state, is an evaluation function.
I used the same one for both the summoning and the attacking phase (you could even unsplit these two parts and evaluate them at the same time). During the contest, I built several functions:
Evaluation function 1 - Complex
The first I built (and the one I used in the end) is a function that takes the following form :
where $B_{me}$ (respectively $B_{opponent}$) is my board (respectively the opponent’s board), and $f$ is an evaluation function for each card, that takes the following (complex form) :
However, I also tried (unsuccessfully) other evaluation function during the contest. A simpler one was talking the same shape as above, but where $f$ was the score of each card from the drafting phase.
Evaluation function 3 - Tempo
The last one was based on the tempo of the player. Here is a definition from an Hearthstone Wiki :
While tempo is often considered to be a common term and fairly simple to understand, it is also often considered to be among the more difficult things in Hearthstone to describe by definition rather than by examples or through a practice run. Many suggestions have been made for verbally describing this use of tempo, some of which are below:
The momentum of the match. Probably the original definition and among many unofficially accepted “right” ones. However, its imprecision can lead to misunderstandings and odd interpretations causing confusion in discussion.
The change of the board state in a given time (usually either a play or a turn, as in “a good/bad tempo play/turn”). What this definition has in its favor is its simplicity, but this very simplicity means that it does not cover all the uses of this term.
The speed at which a player is reaching his/her win condition. An alternate interpretation of the original definition that is especially useful when discussing decks that don’t mainly win by gaining board control or that don’t aim at reaching that goal at the start of the game.
The value of the effect on the board state divided by the mana used. The main upside of this definition is its being in the form of a mathematical formula because in the future it could be applied to calculations.
I tried to evaluate both my and the opponent’s tempo, but this wasn’t successful either. This evaluation was, in fact, pretty complex too, using both players boards and life.
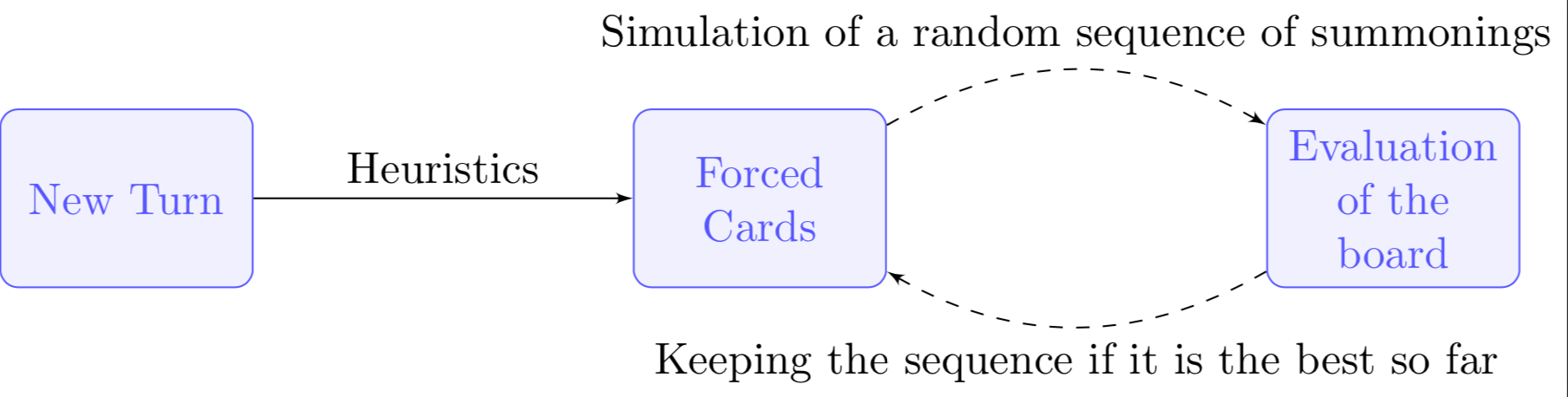
Summoning phase
The summoning phase was kept as simple as possible to waste as little time as possible.
First, I would check if I had to summon some cards. For example, a Guard card could save me if I was about to die, or a Charge card could finish the opponent immediately. Therefore, I would always check first if certain situations occurred and apply them directly.
Once this was done, I would generate a random sequence of possible cards to summon, simulate it, and evaluate the board. If the score was better than the current best, I would keep it.
Representation of the process going on for the summoning phase.
Attacking phase
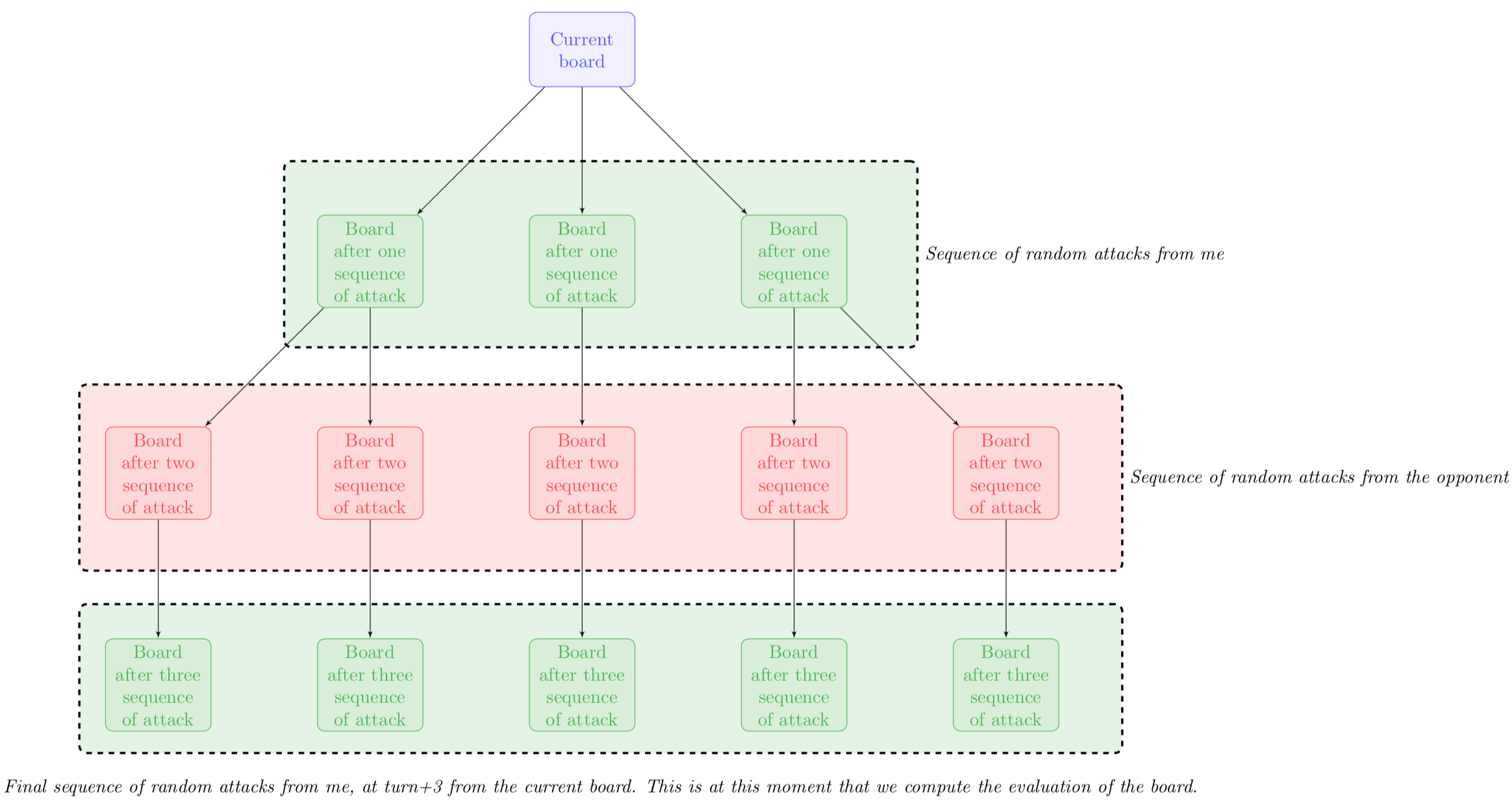
Regarding the attacking phase, my strategy was to implement a depth-3 MCTS, as shown in the figure below.
View of the tree I built during the attacking phase.
However, some minor changes had to be done. First, this scenario simulates attacks from the opponent and the MCTS selection has to be modified: you now have to take into account your loose (or your worst evaluation function) since you want the opponent to be as good as possible. Then, you can’t simulate the whole game until the end, and this is why I decided to stop the expansion phase at depth-3, with an evaluation of the board (rather than a boolean you win, you lose).
Finally, my code took the following form (with the time limit in mind):
Actions
Allocated time
Sending outputs
5ms
Response time for the summoning phase
25ms
Response time for the attacking phase
70ms
Conclusion
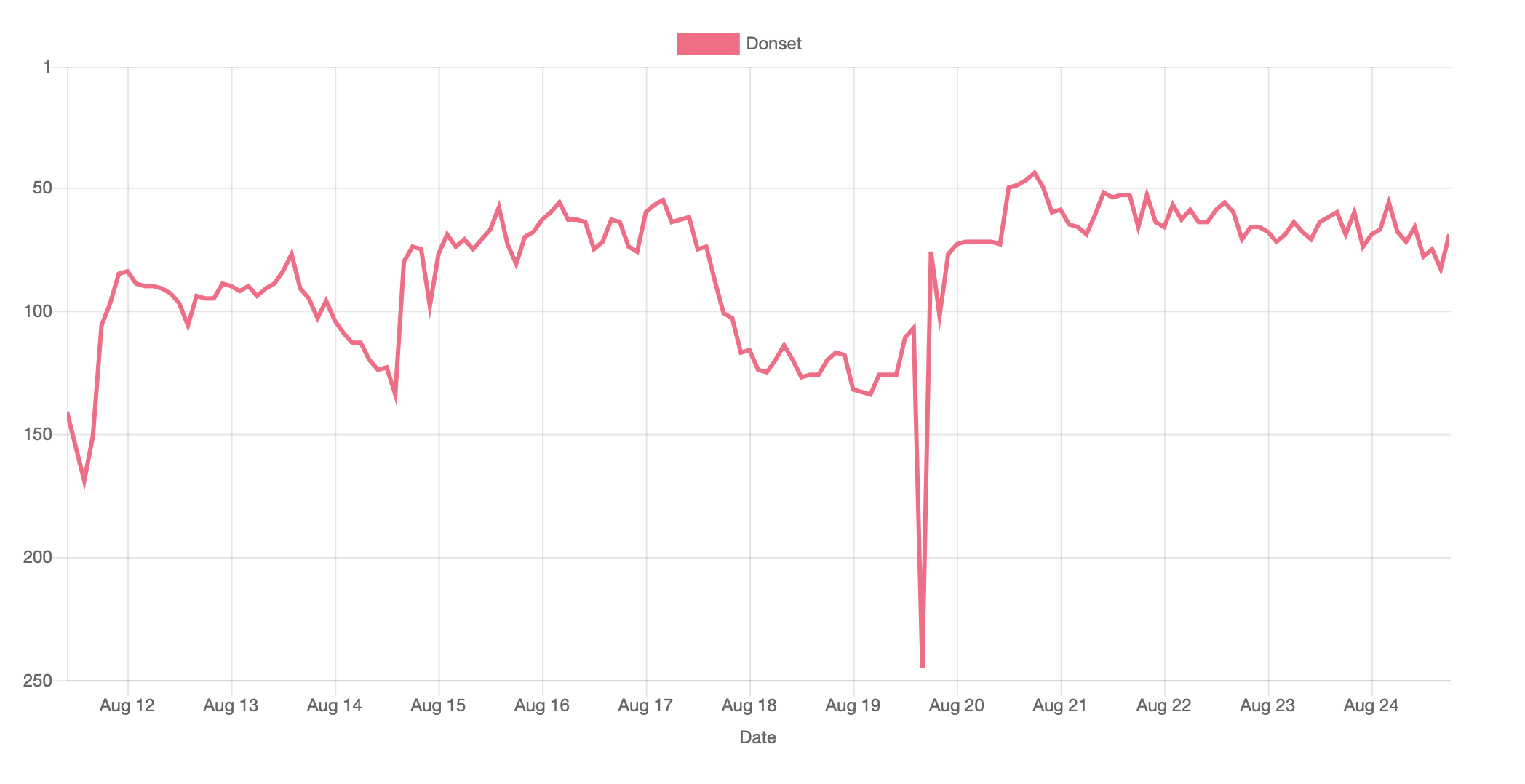
In the end, 2200 people participated in the contest. It was leagues based, and we were around 90 in the final league. To go to a higher league, you need to have a better score than the boss. The score is based on your wins and losses, against other players. You can find below my ranking throughout the contest.
I ended up in the 69th position and the 11th best student.
Overall, it was an enjoyable contest. There was a lot of work to do, a lot of different aspects to take into account; several algorithms could be used: a great game!
My ranking (out of 2,200) some time in the contest.